
Jamie Thomson (SQL Server MVP from the UK) threw out a challenge recently, and it was interesting to see the responses. His question was about string concatenation, and of course, FOR XML PATH(”) made a strong case for itself. It was put into SQL2005 for exactly this purpose. But I noticed that the responses using this pattern also used the DISTINCT keyword, to stop there being duplicate entries in the results.
And this makes for a good opportunity for me to tell you about the difference between DISTINCT and GROUP BY.
They might seem to be quite different, but if you’re not using aggregate functions, the difference stops being so significant. Certainly if you were to run ‘select distinct col1 from table1’ and ‘select col1 from table1 group by col1’, you will notice that actually they are exactly the same. Both will scan through the data, doing a distinct sort on the results.
So now consider the situation in Jamie’s question. To set up the scenario, run the following:
|
1 2 3 4 5 6 7 8 |
USE tempdb GO CREATE TABLE t1 (id INT, NAME VARCHAR(MAX)) INSERT t1 values (1,'Jamie') INSERT t1 values (1,'Joe') INSERT t1 values (1,'John') INSERT t1 values (2,'Sai') INSERT t1 values (2,'Sam') |
The two queries to compare are as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
select id, stuff(( select ',' + t.[name] from t1 t where t.id = t1.id order by t.[name] for xml path('') ),1,1,'') as name_csv from t1 group by id ; |
|
1 2 3 4 5 6 7 8 9 10 11 |
select distinct id, stuff(( select ',' + t.[name] from t1 t where t.id = t1.id order by t.[name] for xml path('') ),1,1,'') as name_csv from t1 ; |
Both return the same data. But if we look at the execution plans, we will see they are executed in different ways. The layman’s way of explaining this is to point out that the ‘distinct’ needs to check that the name_csv field is unique each time as well, whereas the ‘group by’ just needs to check that the subquery is valid – ie, doesn’t refer too any non-grouped fields.
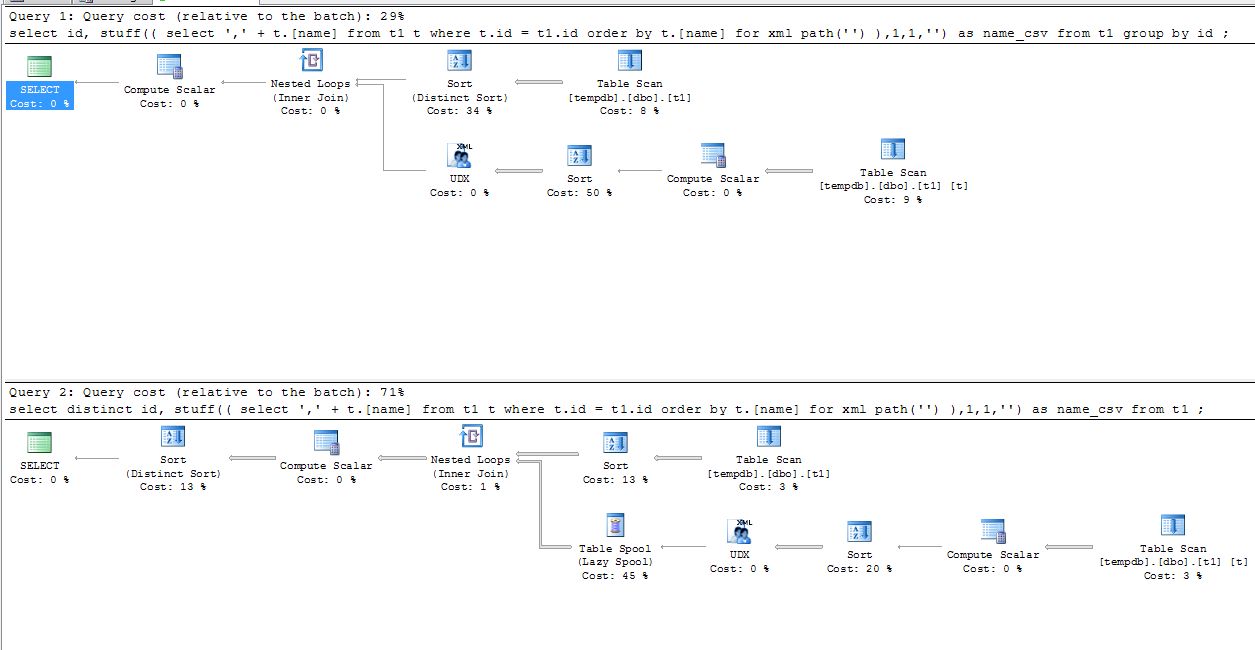
So you can see that the execution plan (and this is the actual, not the estimated) says that the GROUP BY is quicker than the DISTINCT, but if we look at what’s actually going on, we can clearly see that the first query does the Distinct Sort step before the Nested Loop, whereas the second does the Distinct Sort as the very last step.
I have to point out that you can’t always use GROUP BY instead of DISTINCT in an effective way, and nor should you. If returning unique records is actually what you want, then DISTINCT may be better. It’s certainly clearer code in many situations. But if you’re using it just because your code is inadvertently returning more than you want, then you should try to have the DISTINCT apply earlier. This might be with “WHERE EXISTS” instead of a join, or maybe using a “SELECT DISTINCT …” derived table. In a previous post (at my old blog), I showed that ROW_NUMBER() can be used to remove duplicates from a table. So there are certainly different ways to produce a unique set of rows, and it’s worth considering which one is right for you.
This Post Has 4 Comments
Rob, If u do not wants to use COALESCE function in ur T-SQL, then u can use CASE statements for String concatenation.
What say?
Mahesh
COALESCE only helps handle the situations where the string is null. It doesn’t actually assist with the concatenation process itself.
Try
with uniqueT1 as (
SELECT distinct id
from t1
)
SELECT id,
stuff((SELECT ‘,’ + t.[name]
from t1 t
where t.id = ut1.id
order by t.[name]
for xml path(”)),
1, 1, ”) as name_csv
from uniqueT1 as ut1;
—–
Whenever repeated lines occur in the final result, the trick is not to use either DISTINCT or GROUP BY to eliminate the repetitions, but to look for the cause of the repetitions and eliminate them at the beginning.
The above code generates the same execution plan as the one you exemplify using GROUP BY.
Yes, that’s the situation. Your query simulates GROUP BY by separating out the grouping. But I would be reluctant to encourage this pattern because too many people do a separate GROUP BY and then join back to the original table, when all they mean is “GROUP BY the right things!”