
For those people who seek seeks, here’s a “Pro Tip”.
Suppose you have a query that involves a Scan. It can be a Clustered Index Scan or an Index Scan, it really doesn’t matter. If it’s a Table Scan, then you have a Heap in play, and this tip doesn’t apply.
I’m looking for the address in AdventureWorks that’s on Pitt St. I know it’s a tall building, and that the street is in AddressLine2.
|
1 2 3 |
select * from Person.Address where AddressLine2 like '%Pitt Street'; |
This query scans an index called IX_Address_AddressL…something (I’m reading it from the screen, and it’s a little cut-off). Here’s the plan, and I’ve included part of the tooltip so that you can see the scan finds a single row.
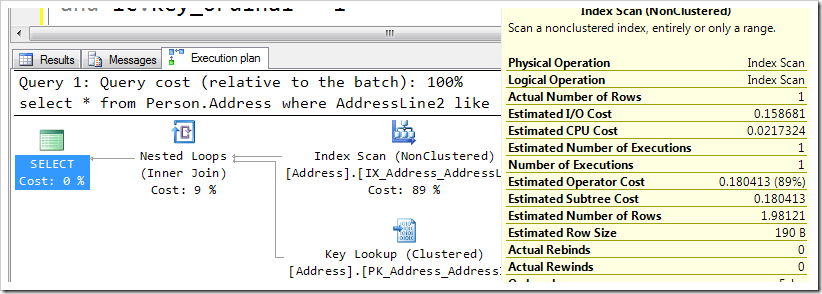
Now, I’ve heard that Scans are bad, and Seeks are better. I’m sure I can make this query seek, without even adding a new index!
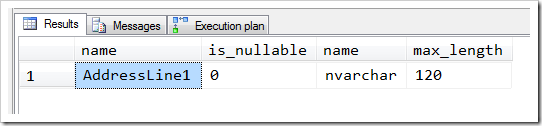
First I run a simple query to look up the first key column in this index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
select c.name, c.is_nullable, t.name, c.max_length from sys.indexes i join sys.index_columns ic on i.object_id = ic.object_id and i.index_id = ic.index_id join sys.columns c on c.object_id = i.object_id and c.column_id = ic.column_id join sys.types t on t.user_type_id = c.user_type_id where i.name like 'IX_Address_AddressL%' and i.object_id = object_id('Person.Address') and ic.key_ordinal = 1; |
This is handy – it tells me it’s AddressLine1, and that’s a non-nullable column of type nvarchar(120).
Now, every value in this column must be at least alphabetically >= than the empty string, so adding the predicate WHERE AddressLine1 >= N” shouldn’t affect the results (it could if it allowed NULLs though, so be careful).
|
1 2 3 4 |
select * from Person.Address where AddressLine2 like '%Pitt Street' and AddressLine1 >= N''; |
And hey presto, I’ve turned the Scan into a Seek! Success! Clearly my performance has been enhanced.

Of course it hasn’t.
In fact, it’s probably marginally worse, because not only am I having to check every row to see if it’s in Pitt Street, but I have to work out where to start. I’m still starting at the beginning of the index, and going through every record, but because we’re performing a search on the key column of the index, the Query Optimizer is actually doing a Seek. It’s just a Seek which is having to scan every row of the table, which is what we generally consider to be a Scan, not a Seek.
If you’ve read some of my recent posts, you will realise that this is because of the Residual Predicate in play. Both tooltips are shown below for your reading pleasure, and you’ll notice that they’re very similar. They have the same Residual Predicate which is doing all the work, it’s just that the Seek is starting off with a Seek Predicate.
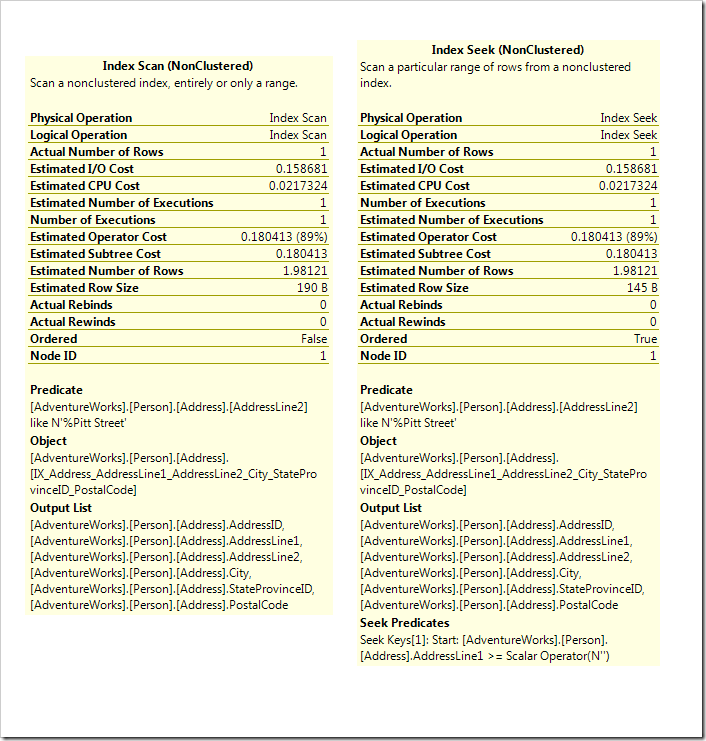
So you see, this Seek is never going to perform better than the Scan. It’s all well and good to recognise that effective usage of indexes involves Seeks, but a Seek isn’t ideal just because it’s a Seek, it has to be Seeking on something effective, highlighted by a selective Seek Predicate.
…and of course, we should’ve done some far more creative indexing, such as introducing a full-text index on AddressLine2.
I’ve also submitted a Connect item to have more information shown in the query plan, at:
https://connect.microsoft.com/SQLServer/feedback/details/670391/more-information-from-seek-operations-in-plans
This Post Has 11 Comments
Hey Rob, if you used Plan Explorer to analyze the plan, among other things, you wouldn’t have to deal with truncated names. 🙂
Plan Explorer still seems to cut that one off – although it does show a bit more. The tooltip shows the whole name in both SSMS and SSPE.
But yeah, I keep feeling tempted to use SSPE for these diagrams, if only because it has the rowcount shown clearly.
Right-click the plan diagram and select "Full Object Names" 🙂
Hi Rob
I just found this post today…
I have a really simple demo in my 5-day internals class where I show a plan that says it’s doing a seek, but it actually looking at every single row in the table. So I stress to my students that just because the plan says ‘seek’, doesn’t always means it’s a great (or fast) plan. You have to look at rowcounts and costs also.
Thanks
Kalen
Sounds good, Kalen. I find so many people fail to appreciate the residual Predicate’s effect on a Seek operation, when the Seek Predicate is not selective enough. I feel like it turns up in almost every tuning exercise, and yet so many people miss it.
I love OPTION (QUERYTRACEON 9130) for giving a better indication about what’s happening. 🙂
Rob
I have other posts that relate to this as well, such as the one called "Covering Schmuvvering", one on "Probe Residual when you have a Hash Match" (not actually about airport security).
I was just linking around to some of your related posts, and found that you have an example almost exactly like mine in this post:
http://sqlblog.com/blogs/rob_farley/archive/2011/05/25/covering-index-because-it-s-covering-up-the-truth.aspx
select *
from Production.Product
where ProductID < 999999999;
I basically explain it like this: There are only 2 operations that can be used on indexes: seeks and scans. And a scan is only used when the optimizer is absolutely sure it will have to look at every single row. And if it can’t be sure it’s a scan, the plan will say seek. Even if it’s a whole lot of rows …
I point out that it’s a Seek if there’s a predicate being used as a Seek Predicate, which essentially the same sentiment. The Seek Predicate can be used to find the start of the RangeScan and then when to stop, while the Predicate is the "check" that is applied to every row in the Range. The Seek Predicate is applied to every row in the Range too, but the reaction of "predicate not satisfied" is to mark the end of the Range (thereby stopping the RangeScan).
Visit below link for more details on Scan Vs Seek
Scan indicates reading the whole of the index/table looking for matches – the time this takes is proportional to the size of the index.
Seek, on the other hand, indicates b-tree structure of the index to seek directly to matching records – time taken is only proportional to the number of matching records.
technowide.net/2015/02/18/move-scan-seek/
Hi Sachin,
I’m sorry, but you’re somewhat wrong.
A Scan starts at the beginning of the index (or at the end of it’s going backwards) to look for matches. It stops when it stops being asked for more records, or when it has looked through the index. A Seek starts at a particular position and then scans through a particular range. It also stops when it stops being asked for more records, or if the range it is looking through is done.
While the range of a Seek might be smaller than the whole index, it might not be.
Also – in your post you say that a Clustered Index Scan is better than an Index Scan. That’s almost never true. You also say that a Table Scan is the worst, but that is also very contentious.
Your post talks about the number of rows that satisfy the Predicate. You actually mean the Seek Predicate. As I showed in this post, if the Seek Predicate satisfies just about every row, then the Seek becomes worse than the Scan, which is hidden by the selectivity of the Predicate.
I feel like your comment is just trying to lure people to your website – and I will remove the link soon as I don’t consider your website is helpful, and is even wrong in some situations.
Rob
Thank you Rob for this, I am new to SQL server and this post helped me get rid of the seek/scan myth associated with indexes. Most people are stuck on somehow achieving a seek, while a scan would give the exact same performance.
Regards,
Athul