
In my last post, I showed a technique for dealing with working columns when writing T-SQL. The idea was around using APPLY to be able to push values from the existing set through calculations (but preferably not scalar functions, of course), producing new columns which can be used further down the query, even in the WHERE and GROUP BY clauses. Useful stuff indeed.
But there is a limitation which I didn’t cover, and I feel that this is worth writing about for this month’s T-SQL Tuesday.  The theme allows people to write about previous Tuesday topics – so I’m going to revisit topics 17 and 25 as I go a little further into APPLY.
The theme allows people to write about previous Tuesday topics – so I’m going to revisit topics 17 and 25 as I go a little further into APPLY.
These working columns can only be applied if they are calculations on a single row of data. The resulting set might be bigger or smaller based on how many rows are affected, but the input (at least logically) should be considered on a row-by-row basis.
Consider the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT p.Name, r.RevName FROM Production.ProductSubcategory AS s CROSS APPLY (SELECT REVERSE(s.Name) AS RevName) AS r CROSS APPLY ( SELECT TOP (1) * FROM Production.Product AS p WHERE p.ProductSubcategoryID = s.ProductSubcategoryID ORDER BY p.ListPrice DESC ) AS p ORDER BY s.ProductSubcategoryID; |
You see two CROSS APPLYs here – one creating a simple working column in REVERSE(s.Name), the other even involving another table to do a lookup. This second CROSS APPLY doesn’t necessarily produce any rows – if there is no matching Product, the resultset won’t contain any rows for that ProductSubcategory. I’ve shown some of its results below:
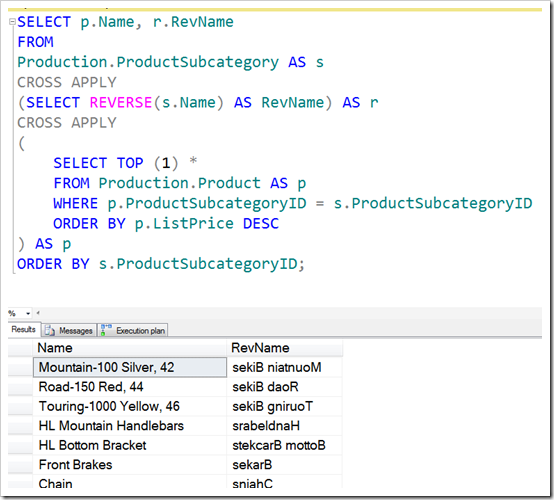
But what about the following query, which gives the same 37 rows on the AdventureWorks database:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT ( SELECT TOP (1) p.Name FROM Production.Product AS p WHERE p.ProductSubcategoryID = s.ProductSubcategoryID ORDER BY p.ListPrice DESC ), REVERSE(s.Name) AS RevName FROM Production.ProductSubcategory AS s ORDER BY s.ProductSubcategoryID; |
This is very similar, but you’ll notice that instead of developing the result set in the FROM clause, I’ve used the calculations directly in the SELECT clause to produce the same result.
Except that it’s not the same.
Here, my TOP sub-query can only produce a single value. You’ll notice I change my query to fetch only a single column now – any more would give an error. And I’m lucky I’ve selected TOP(1), not TOP(2), or TOP (1) WITH TIES – which would both be legal in my APPLY system. You’ll see that APPLY provides additional flexibility here.
So now consider the following query:
|
1 2 3 4 5 6 |
SELECT p.Name, p.ProductSubcategoryID, COUNT(*) OVER (PARTITION BY p.ProductSubcategoryID) AS SubcatCnt FROM Production.Product AS p ORDER BY p.ProductSubcategoryID, p.Name; |
You will see that both look at the list of Products, and produce a count of the number of products which are in the same Subcategory. I’m sure you’re all very familiar with the OVER clause and the use of the windowing technique provided by the PARTITION BY clause.
If we run this first query and look at some of the results, you’ll see the marvellous windowing technique, which I’ve highlighted using ZoomIt. You’ll see that the SubcatCnt column has the value 3 for the Subcategory with 3 items, and 6 for the one with 6, and so on.
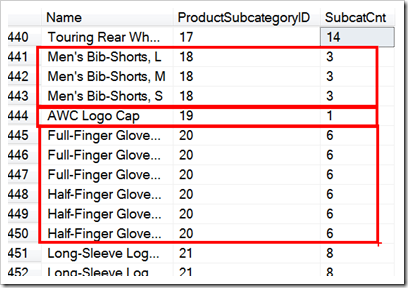
Excellent stuff. But you’ll probably also be aware that you can’t use windowing functions like this in the WHERE clause – they’re applied only in the SELECT clause.
Having seen my working columns trick though, you might think otherwise.
Check this out – it’s perfectly legal!
|
1 2 3 4 5 6 7 8 9 10 |
SELECT p.Name, p.ProductSubcategoryID, sc.SubcatCnt FROM Production.Product AS p CROSS APPLY ( SELECT COUNT(*) OVER (PARTITION BY p.ProductSubcategoryID) AS SubcatCnt ) AS sc ORDER BY p.ProductSubcategoryID, p.Name; |
Amazing stuff. I can now use SubcatCnt in the WHERE clause. Job done!
But I’m having you on. It’s a trick. It’s rubbish.
You see, APPLY logically works on a single row at a time, as I said earlier. Look at the same block of results for this second query.
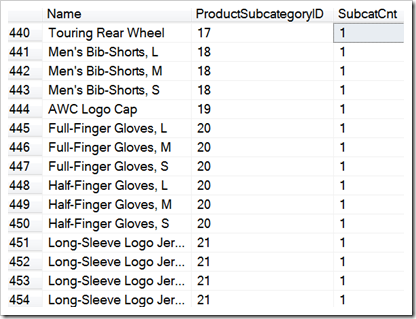
Loads of 1s. Not exactly helpful. It’s accurate though – there is a count of one row in each partition of the set that is logically passed in each time.
APPLY works out the result for each row individually. It doesn’t do it for the whole set. So if you’re wanting working columns that need to be applied to multiple rows at once, then you need to think of another solution.
APPLY is good, but not that good. Know its limitations and you’ll be better off.
This Post Has 4 Comments
Hey, thanks for picking up my topic again! This is all really fantastic stuff you’ve been sharing about APPLY.
Haha, yeah. I’m pretty sure a few months ago I refactored a statement using an APPLY/RANK combination and found out the same thing as you at the end 🙂 Many a keyboard thumping was had that day!
Simple enough, – APPLY is not a statement of the ISO ANSI SQL language standard. What’s not standard better not be used.
Would another solution be chaining multiple CTEs together?