
I am NOT suggesting that data integrity is irrelevant. Not at all. But how often do we need an enforced primary key or foreign key?
Be warned – I’m not actually going to come to a conclusion in this post. I’m going to make cases for both sides, and let you choose where you stand. The T-SQL Tuesday topic this month is Integrity, so some other people might have written on a similar topic, and produce even more compelling arguments one way or another. I’m the host this time, so you’ll be able to find the round-up (once it’s there) here on the LobsterPot Solutions site too.
Relational theory tells us that all the information in a row of data should relate to the primary key value. Therefore, we can use that primary key value to refer the salesperson / product / whatever, in other tables. The value itself doesn’t need to be unique across the whole database (like a guid would be), but it does need to be unique in the context of salespeople / products / whatever. In the AdventureWorks sample database product 843 is the Cable Lock. If that ProductID value were not unique, we might know that someone has bought product 843, but not actually know what it is. 843 can obviously mean other things in other tables, but if it’s referring to a product, that’s the Cable Lock.
These rules are relevant even if we’re not using a relational database like SQL Server or Oracle. In your analytics system, when you indicate that someone has bought product 843, you should still know what that means, even if you’re using a data lake or other big data solution. Even if you don’t use IDs and refer to a product by its name, size, and colour, you need to be able to tell exactly which product it is.
So therefore, it’s very important to be able to have confidence that there is only one “product 843” in the product list. From a logical perspective, we should know that the product ID is unique and we’ll have trouble if it’s not. And considering foreign keys, we should be confident that if we refer to product 843, that there actually is a product 843 at all.
But do we need the underlying technology to enforce these keys?
There are definitely reasons to do so, and also reasons not to. The responses I find people usually give in favour of enforcing are “what if you get a duplicate ID value?” and “what if you get an orphaned row?” – and to them, I say:
“Ok, when did you last get a key violation error in your application?”
Considering most relational database tables use identity columns or sequence-based defaults, the answer is only when someone has been messing around in the back, circumventing the application, explicitly providing values for the PK column. Similarly with FK violations – your application doesn’t (ok, shouldn’t) make those mistakes. Any time something gets deleted, I’m sure your application meticulously deletes all the rows that reference it, just as if you’d defined the FK with ‘on delete cascade’ (but doing it manually, because no one seems to trust that “on delete cascade” will be okay). The same with your PK values – I’m sure your application / database isn’t generating duplicate values. Something would have to be very very wrong.
Having a unique index or constraint on a column which isn’t auto-generated – that’s a different matter. If you have a code for each product that has been chosen individually by hand, then a unique constraint can be useful for making sure they really are unique. The application probably tells you “sorry this is taken” before you can save it, and just in case two people try to save the same one at almost the same time, telling the database layer to enforce it can be useful.
But let’s not pretend that we actually need these constraints to have a working database system.
Otherwise, SQL Data Warehouse in Azure Synapse (from the days before Fabric) would support keys, and Fabric Data Warehouse would make sure that their primary and foreign keys were enforceable.
Yes, you’re reading that right. The documentation for Fabric Data Warehouse makes it very clear. You can create keys, but they’re not enforceable. If you create them, you’re doing it for the sake of metadata, so that when you point something like Power BI at it, it can tell where the relationships are.
And this is a valid reason. Metadata is important. In fact, metadata like this is a good reason to have foreign keys in all your databases.
But it’s more than that.
By knowing that a particular column is unique, you get some performance benefits for certain queries.
In the AdventureWorks database, when counting the number of products by subcategory name (a query I seem to use regularly when explaining concepts), it’s more work for the SQL Server engine if there is no unique index on the Name column. The database comes with a unique index on Production.ProductSubcategory.Name, so I have a copy of the table without that index.
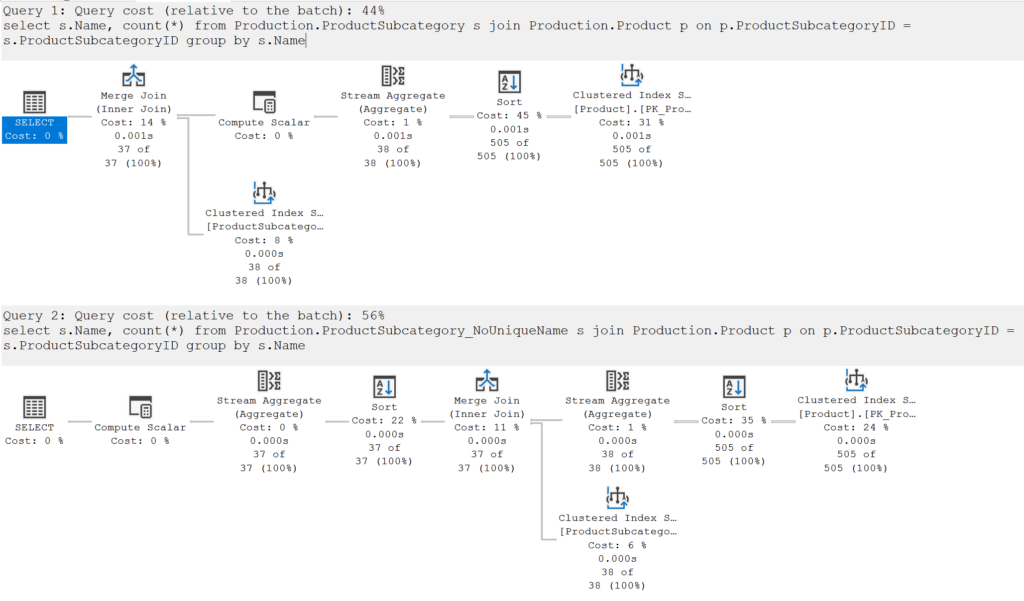
If you have an index on data that you know to be unique, then enforcing it can make the index slightly smaller. At all levels of an index in SQL, the engine needs to be able to identify each row. If it’s not unique, the clustered index details (or RowID if there isn’t one) that uniquely identify each row (including a ‘uniquifier’ value if the clustered index is not a unique clustered index) need to be stored everywhere the indexed values appear. Whereas if the index is unique, those clustered index details only need to be stored at the leaf level. This can be a very real benefit to marking an index as unique. It should be pointed out that the effort to maintain a unique index is typically no more than the effort to maintain a non-unique index – the location of the row to be maintained still needs to be found, and space made / pages split if needed.
But maintaining a unique index does get complicated by partitions or other kinds of distribution. It’s significant work to make sure that values are unique across separate locations. It’s a very different proposition to having a single index with the value either there or not there. If you had 60 distributions in your SQL DW environment, those keys suddenly become a lot more work to maintain – both for PKs and for FKs.
Even without distributed data, if you’ve ever tried to delete a bunch of rows in a table that has over a hundred foreign keys pointing at it, you’ll know there can be pain. You can always do a manual delete of all the referencing rows, but even if you’ve done this the SQL engine will still need to check when you delete the parents.
Foreign keys aren’t all bad though. The confidence from FKs of knowing that a value must be present in a table and that there must be exactly one matching row can be leveraged by the SQL engine. Knowing how many rows to expect is important – cardinality estimation is critical to knowing the best way to execute a query.
Let’s use my “Production.ProductSubcategory_NoUniqueName” table again, which has a non-unique clustered index, and no foreign key relationship between it and Production.Product. I’m going to do a simple join between the two tables, for those products that do actually have a ProductSubcategoryID.
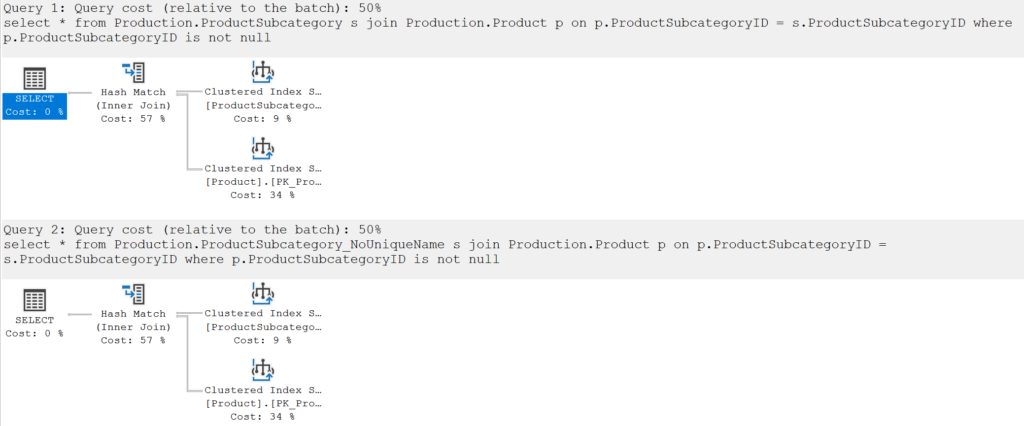
The plans look the same – but how about those cardinality estimates?
Well, it turns out that the estimated number of rows coming out of the Hash Match join operator is exactly the same as the number of rows estimated to be coming out of the Product table. It matches despite the absence of the unique index. Even though there is a chance there could be more or fewer rows on the non-unique one, the estimate suggests there won’t be.
And the reason is statistics. It’s not about anything that is enforced. It’s just something that’s been observed. The system can see that there is one row per value, and although it can’t be completely sure it’s enough to get good cardinality estimates.
If the SQL engine could be completely sure of the foreign key, then it could do a neat trick of removing the join if we only wanted rows from the Product table.
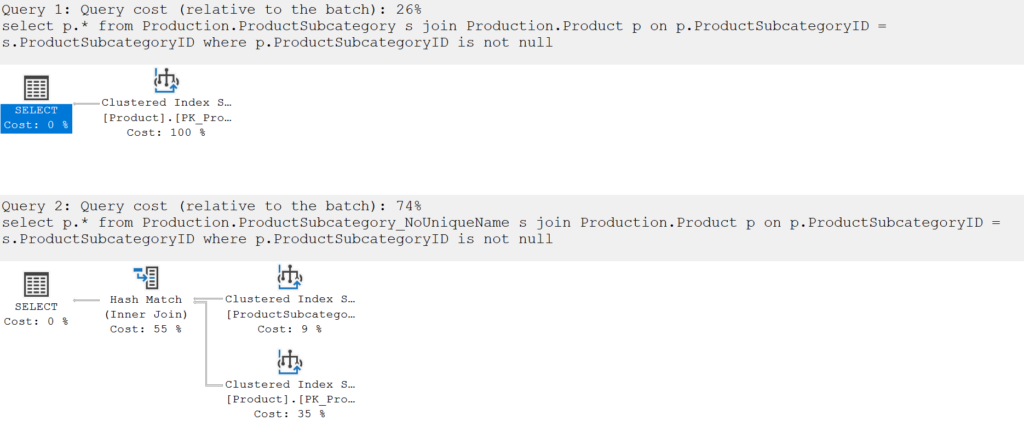
But the statistics are enough to for the cardinality estimations to be good. The SQL engine isn’t expecting there to be duplicates or missing values – it just can’t guarantee it.
There are clearly some benefits to having enforced referential integrity. But perhaps it’s not quite the requirement you’ve considered it to be. I’m not going to say you shouldn’t use enforced keys, but I’d also like to encourage not to dismiss Fabric DW just because you can’t enforce your keys.
As for the integrity of people – this can never be enforced. Maintain your personal integrity yourself, and hopefully people will observe that statistically, you’re pretty reliable.
@robfarley.com@bluesky (previously @rob_farley@twitter)