
Some people have missed the point about my last post, called Covering, Schmuvvering. If you haven’t read it, then do so. Have a think about what’s going on, and why the Covering Index really isn’t that good, and then come back here and see if you’ve understood it right.
My point is that often in a Seek, the Seek Predicate isn’t filtering out much of the data, and we’re left with a Seek which isn’t much better than a Scan.
The plan that I didn’t show in the last one is the one that follows. To make this, I’ve created a non-covering index, and forced (by hinting – you know, one of those hints that husbands understand isn’t really a ‘hint’ at all) the Query Optimizer to use it.
|
1 2 3 4 5 6 7 |
CREATE INDEX rf_ix_NotCovering2 ON Production.Product(DaysToManufacture); SELECT Name, ProductNumber FROM Production.Product with (index(rf_ix_NotCovering2)) WHERE DaysToManufacture < 4 AND ReorderPoint < 100 AND Color = 'Red'; |
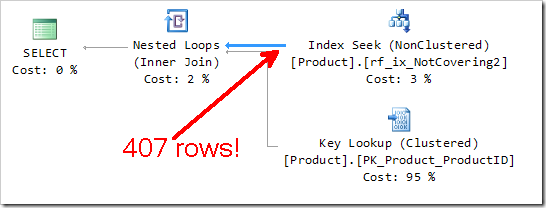
The tooltip on this Seek shows that the Residual Predicate is no longer in play here. It can’t be – the included columns from the previous post simply aren’t there any more. (If you’re wondering what I’m talking about, then remember I did ask you to read the first post first)

A covering index is simply there to remove the cost of having to perform the Key Lookup – and rightly so, those things are expensive! We really can eliminate a big chunk of the cost of this query by using a covering index. But it’s the size of that arrow that concerns me.
The Seek Predicate here, testing the DaysToManufacture field, is the same Seek Predicate used in the original Covering Index Seek operation (from the earlier post, shown below). It still returns 407 rows, which each need to be checked to see if they satisfy the Residual Predicate.
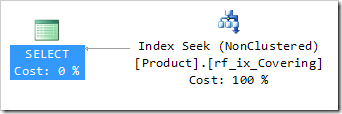
The Covering Index Seek operation here feels very similar to the box I’ve drawn here around some of the operations in the Lookup scenario. You’ll notice a Single Row arrow coming out of the box. But most importantly, you’ll notice the big thick arrow coming out of the Seek Predicate bit.
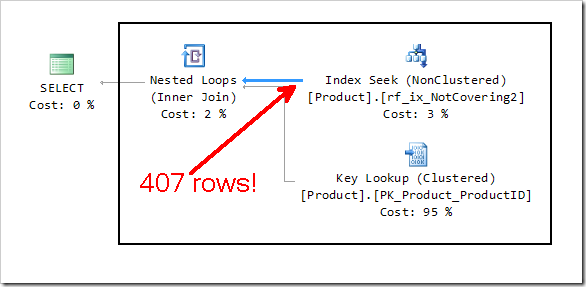
Yes, that Residual Predicate, testing Color and ReorderPoint needs to be performed 407 times – that’s how many times our Key Lookup is performed.
With our Covering Index plan, it’s much harder to see. In the diagram below, I’m showing the Tooltip from the original Covering Index plan, showing where features correlate to the plan with the Key Lookup. I’ve drawn arrows to show you what corresponds to what. Remember this is the tooltip from the Covering Index, with arrows pointing at the Non-Covering Index example. The green arrow shows the Seek Predicate, which is located in the Index Seek on rf_ix_NotCovering2. The pink arrow shows where the Residual Predicate is being applied. The blue arrow shows us where we see a single row being returned. What we DON’T see in the tooltip is that the Seek Predicate is satisfied by 407 rows.

The Covering Index Seek shows us that a Seek is being done, and it shows us that a single row is outputted. What it doesn’t show us is that our Seek could pretty much be a scan.
In fact, I can easily demonstrate a Seek which is no better at all than a Scan.
|
1 2 3 |
select * from Production.Product where ProductID < 999999999; |

This is a Seek. It says it’s a Seek. There’s even a Seek Predicate involved, which is doing a Seek.

But of course, all the rows in the Clustered Index are returned. It’s the same as a Scan. The Estimated Subtree Cost is exactly the same as a Scan, because it’s performing a Range Scan where the Range just happens to be the whole table. I could even put in a Residual Predicate (like AND reverse(Name) = ‘niahC’), to make it look like it’s an effective Seek.
|
1 2 3 4 |
select * from Production.Product where ProductID < 999999999 and reverse(Name) = 'niahC'; |


Don’t fool yourself into thinking that this CIX Seek is good – this is still scanning the entire table, checking every row to see if the name spells ‘nianC’ backwards. It’s just that the plan doesn’t tell us how many rows are satisfying the Seek Predicate, and therefore having to be checked by the Residual.
I hope you see why a Covering Index can often hide the truth. If you just look on the surface, things can seem rosy. A Seek returning a small number of rows is good. But included columns can’t be involved in a Seek Predicate, and if your Seek is hardly better than a Scan, you could well be failing to realise the true benefit of a Covering Index.
Use Covering Indexes they way they were intended – to include things that are being returned by your query, not things that need to be tested. And try forcing a non-covering index to be used, to get a feel for just how thick that arrow is – the one that a Covering Index covers up.
This Post Has 11 Comments
I do not believe this. "Covering indexes good, clustered scans bad" – everybody with 1+ month of experience knows it! You should do some research before posting your half-baked "insights" 😉
I really hope everyone notices your wink there, Alex. 🙂
Reading this for the first time today, and I agree with the sentiment, but disagree with the demo.
The "Covering index" created for the sample is not a true covering index. Columns that should be in the key of the index are in the Includes list.
I’m assuming that this was contrived on purpose to demonstrate how a covering index seek may not be any better than a clustered scan. Let’s skip the whole fill factor aspect of it for now. This was admittedly contrived to force the seek of the covering index to require more logical reads (16) than the clustered index scan (15). Setting fill factor to the default value (100) reduces the logical page reads to 7.
However, even more telling is that simply creating the correctcovering index reduces the page reads to 2.
Using your example, I created the 2 following indexes:
CREATE INDEX rf_ix_Covering ON Production.Product(DaysToManufacture)
INCLUDE (Name, ProductNumber, Size, ReorderPoint, Color);
CREATE INDEX rf_ix_TrueCovering ON Production.Product(Color, DaysToManufacture, ReorderPoint)
INCLUDE (Name, ProductNumber, Size) ;
Then I ran the following forms of the query forcing it to use your covering index, the clustered index, and allowing it to pick its own index (it uses the covering index I created). I also used the recompile option and enabled Statistics IO and actual execution plan settings:
SELECT Name, ProductNumber
FROM Production.Product with(index(rf_ix_Covering))
WHERE DaysToManufacture < 4
AND ReorderPoint < 100
AND Color = ‘Red’
Option(recompile)
SELECT Name, ProductNumber
FROM Production.Product with(index(1))
WHERE DaysToManufacture < 4
AND ReorderPoint < 100
AND Color = ‘Red’
Option(recompile)
SELECT Name, ProductNumber
FROM Production.Product
WHERE DaysToManufacture < 4
AND ReorderPoint < 100
AND Color = ‘Red’
Option(recompile)
Statistics IO output (with row counts removed and LOB counts truncated) was:
Table ‘Product’. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0…
Table ‘Product’. Scan count 1, logical reads 15, physical reads 0, read-ahead reads 0…
Table ‘Product’. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0…
And the actual execution plans showed that the cost of the three queries when executed as a single batch are respectively 29%, 56%, and 15% of the total cost of the batch. This clearly demonstrates that the "bad covering index" is almost 50% the cost of the clustered index scan, and twice the cost of using the appropriate covering index.
Hi Robert,
Thanks for your comment.
I agree that a better index could be used. But my point is that a Covering Index Seek hides a lot of the truth if you don’t know to look at the Residual Predicate.
But tell me – why have you put ReorderPoint in as your third key? Can you explain why you consider this is better than having it in the Included list?
Rob
Of course, Robert, the ideal index for this query is the filtered index that I put at the end of the original post (http://sqlblog.com/blogs/rob_farley/archive/2011/05/19/covering-schmuvvering-when-a-covering-index-is-actually-rubbish.aspx), which causes an Index Scan that doesn’t check the predicates at all.
Hi Rob,
Another important consideration people overlook with seeks is how it knows when to stop…
Just thought I’d chip that in ;c)
Paul
Indeed Paul. A filtered index is definitely better, and if it’s covering as well, then great. A filtered index whose predicates match the query’s predicates doesn’t even need to check what’s there, it just grabs all the rows. It’s a thing of beauty, with no Residualicity.
Excellent point Rob. Having a 2nd inequality value in the index doesn’t improve the usage. If anything, it will make the index a little bit bigger.
Anywho, I definitely agree with what you are saying here. I just got distracted by the fact that the covered index shouldn’t have been used in the first place.
No problem, Robert. I figure there are scenarios where an Index Seek is in place, and people just assume it’s ideal, because people just love Seeks and hate Scans.
The important point here is that consider the amount of rows being fetched and the number of executes involved in evaluating the join/filter condition in the plans. This is one of the reason I am still a fan of the text execution plan format. It lets me look at the operator, residuals, rows and executes along with the estimates. However, I am old school and people might differ with me on the use of text vs XML plans.
Just because it’s a SEEK doesn’t mean that you have the best plan! That is an urban-legend. 🙂
Hi Amit,
Not quite. There is nowhere that tells us how many rows are being satisfied by the Seek Predicate and then need to be checked by the Residual.
But for the mostpart, I agree with you wholeheartedly.
Thanks for the comment!