

MERGE is very cool. There are a ton of useful things about it – mostly around the fact that you can implement a ton of change against a table all at once. This is great for data warehousing, handling changes made to relational databases by applications, all kinds of things.
One of the more subtle things about MERGE is the power of the OUTPUT clause. Useful for logging.

If you’re not familiar with the OUTPUT clause, you really should be – it basically makes your DML (INSERT/DELETE/UPDATE/MERGE) statement return data back to you. This is a great way of returning identity values from INSERT commands (so much better than SCOPE_IDENTITY() or the older (and worse) @@IDENTITY, because you can get lots of rows back). You can even use it to grab default values that are set using non-deterministic functions like NEWID() – things you couldn’t normally get back without running another query (or with a trigger, I guess, but that’s not pretty).
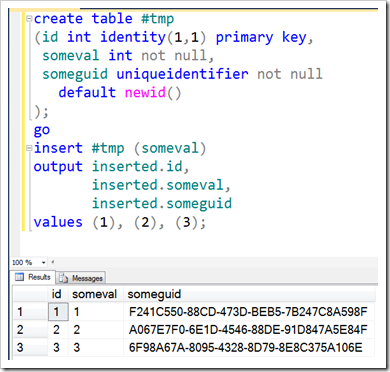
That inserted table I referenced – that’s part of the ‘behind-the-scenes’ work that goes on with all DML changes. When you insert data, this internal table called inserted gets populated with rows, and then used to inflict the appropriate inserts on the various structures that store data (HoBTs – the Heaps or B-Trees used to store data as tables and indexes). When deleting, the deleted table gets populated. Updates get a matching row in both tables (although this doesn’t mean that an update is a delete followed by an inserted, it’s just the way it’s handled with these tables). These tables can be referenced by the OUTPUT clause, which can show you the before and after for any DML statement. Useful stuff.
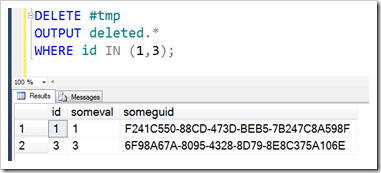
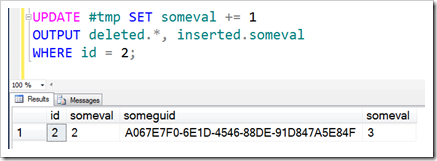
MERGE is slightly different though.
With MERGE, you get a mix of entries. Your MERGE statement might be doing some INSERTs, some UPDATEs and some DELETEs. One of the most common examples of MERGE is to perform an UPSERT command, where data is updated if it already exists, or inserted if it’s new. And in a single operation too. Here, you can see the usefulness of the deleted and inserted tables, which clearly reflect the type of operation (but then again, MERGE lets you use an extra column called $action to show this).

(Don’t worry about the fact that I turned on IDENTITY_INSERT, that’s just so that I could insert the values)
One of the things I love about MERGE is that it feels almost cursor-like – the UPDATE bit feels like “WHERE CURRENT OF …”, and the INSERT bit feels like a single-row insert. And it is – but into the inserted and deleted tables. The operations to maintain the HoBTs are still done using the whole set of changes, which is very cool.
And $action – very convenient.
But as cool as $action is, that’s not the point of my post. If it were, I hope you’d all be disappointed, as you can’t really go near the MERGE statement without learning about it.
The subtle thing that I love about MERGE with OUTPUT is that you can hook into more than just inserted and deleted.
Did you notice in my earlier query that my source table had a ‘src’ field, that wasn’t used in the insert? Normally, this would be somewhat pointless to include in my source query. But with MERGE, I can put that in the OUTPUT clause.

This is useful stuff, particularly when you’re needing to audit the changes. Suppose your query involved consolidating data from a number of sources, but you didn’t need to insert that into the actual table, just into a table for audit. This is now very doable, either using the INTO clause of OUTPUT, or surrounding the whole MERGE statement in brackets (parentheses if you’re American) and using a regular INSERT statement.
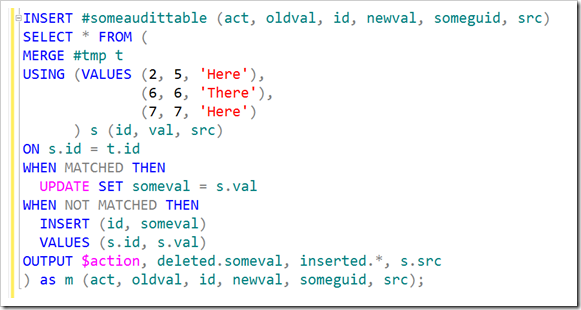
This is also doable if you’re using MERGE to just do INSERTs.
In case you hadn’t realised, you can use MERGE in place of an INSERT statement. It’s just like the UPSERT-style statement we’ve just seen, except that we want nothing to match. That’s easy to do, we just use ON 1=2.
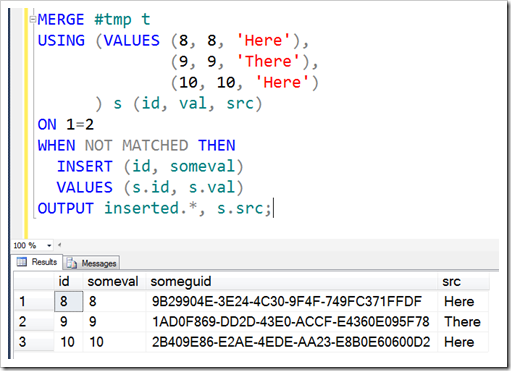
This is obviously more convoluted than a straight INSERT. And it’s slightly more effort for the database engine too. But, if you want the extra audit capabilities, the ability to hook into the other source columns is definitely useful.
Oh, and before people ask if you can also hook into the target table’s columns… Yes, of course. That’s what deleted and inserted give you.
This Post Has 23 Comments
Rob,
Great post, I use the OUTPUT clause quite regularly – especially to populate rollback tables on production data changes but I never knew about $action or the ability to reference other columns from the WITH block.
Thanks
Thanks Greg. And it’s worth remembering that this is only available with MERGE – the other commands only let you hook into inserted and deleted.
Hi Rob. Very interesting scenario of using merge for audit. Goes to my KB.
Maybe, it is worth saying, the case of using merge for insert is very convenient to get rid of cursors when copying linked entities. I blogged about it sometime ago. For example, if we have classical scheme: Customer<- Order <- OrderDetail and a need to copy orders from one client to another. With help of merge we may get a table of links: (OrderID_old, OrderID_new). And after that, use it in join, to copy all the order details at once, in one single query.
Very nice article! I came accross it while searching for an elegant solution to a problem very similar to the one SomewhereSomewhat describes. Definately added to my toolkit.
Yes, definitely.
Ilmar – you’re more than welcome. Good you found it helpful.
Hi Rob,
Is multiple ‘OUTPUT INTO’ clauses allowed
UPDATE …
OUTPUT Deleted.*
INTO @oldValues
OUTPUT Inserted.*
INTO @newValues
WHERE id = @id
Currently using
UPDATE …
OUTPUT Deleted.*
INTO @oldValues
OUTPUT Inserted.*
INTO @newValues
WHERE id = @id;
INSERT @newValues…
SELECT *
FROM ..
WHERE id = @id
I am able to do a OUTPUT INTO and OUTPUT but gives an error when I use multiple OUTPUT INTO
Hi Deege,
This is correct. You can use only one OUTPUT .. INTO and only one OUTPUT clause. But you can use one of each in a single query.
Rob
Rob, you are a god.
Well done on being the only person on the net to point this out. Saved me hours.
Not a god. Just happy to help.
Rob thanks for the reminder about $action, I often forget that is available. However I wanted to make one correction. The only DML statement that you can’t use source data in the output clause is the INSERT statement. You can capture data form the source for UPDATE and DELETE statements as well as MERGE. It is also important to point out that you can add variables, functions, and constants in the output clause caolumns as well. Here are examples:
DECLARE @Colors TABLE (
ID INT IDENTITY PRIMARY KEY,
Color VARCHAR(50)
)
;
DECLARE @DataSource TABLE (
ID INT IDENTITY PRIMARY KEY,
Color VARCHAR(50),
DateModified DATE,
[Action] VARCHAR(50)
)
;
DECLARE @Audit TABLE (
ID INT,
PreviousColor VARCHAR(50),
NewColor VARCHAR(50),
OrignalDateModified DATE,
DateModified DATE,
[Action] VARCHAR(50)
)
;
INSERT INTO
@Colors (Color)
VALUES
(‘Red’),
(‘Blue’),
(‘Yellow’)
;
INSERT INTO
@DataSource (Color, DateModified, [Action])
VALUES
(‘Yellow’, ‘20130207’, ‘Update’),
(‘Red’, ‘20130210’, ‘Update’),
(”, ‘20130212’, ‘Delete’)
;
UPDATE
@Colors
SET
Color = DS.Color
OUTPUT
INSERTED.ID,
DELETED.Color,
INSERTED.Color,
DS.DateModified,
SYSDATETIME(),
‘Updated’
INTO
@Audit
FROM
@Colors C
JOIN @DataSource DS
ON DS.ID = C.ID
AND DS.[Action] = ‘Update’
DELETE
C
OUTPUT
DELETED.ID,
DELETED.Color,
DS.Color,
DS.DateModified,
SYSDATETIME(),
‘Deleted’
INTO
@Audit
FROM
@Colors C
JOIN @DataSource DS
ON DS.ID = C.ID
AND DS.[Action] = ‘Delete’
SELECT
*
FROM
@Audit
Hi Rob,,
I am using MERGE Statement in which there are three tablse source target and history table
Source –It acts as an intermediate stage table
Target –It would be the final table
History– It would be used as an audit purpose which captures the updated records which also consists of two not null columns
When there is no data in target table and History table the output port is sending the updated records with NULL value for which it is throwing error but actually it is not updating any of records how can i avoid such kind of situation..Its only happening when data in target and History are not available when there is data in target the functionality is working fine
Can you suggest me a solution how to fix this
Hi Aditya – Can you send me your code? My email address is on the right…
You can access data other than the inserted/deleted in an output clause, but it has to be joined.
There’s examples on the OUTPUT clause MSDN page, example E is where I got the idea to try self join.
http://msdn.microsoft.com/en-gb/library/ms177564(v=sql.105).aspx
but try this:
UPDATE #tmp
SET someval += 1
OUTPUT deleted.*, inserted.someval, t.id
FROM #tmp
INNER JOIN #tmp as t ON #tmp.id = t.id
I don’t know why exactly, but its probably something to do with not being able to use values on the table directly being changed, but joining to its self seems to work.
I did this on SQL server 2008R2
Saves having to delve into using merge statements if you just want to get other data in an OUTPUT from a simple update.
Thanks Mark – that’s an interesting idea. 🙂
Thanks for this great explaantion of the OUTPUT/$ACTION – very useful.
I used the MERGE statement to update a SCD2 Dimension and it’s great that it can be done in a single step iso multiple steps and temp tables. I now require to capture the Audit info as well and this function helps with this requirement as well. Here’s an exmaple used inside a stored proc to return the audit info
DECLARE @Results TABLE(Action VARCHAR(20));
/…….Merge statements here…../
OUTPUT $action INTO @Results;
SELECT @Insert=[INSERT],
@Update=[UPDATE],
@Delete=[DELETE]
FROM (SELECT Action,
1 ROWS
FROM @Results) P
PIVOT (COUNT(ROWS)
FOR Action IN ([INSERT], [UPDATE], [DELETE])) AS pvt;
Hi Rob,
I was working on a requirement where i need to access inserted.* values and values from the Select List in the output clause for an insert statement. I am working in 2005 so i cannot use merge statement which i know is the other way around but wanted to clear my doubt that its techinically not possible or i am missing something.
PFB, the code part.
INSERT INTO ExternalEmployeeNumber(ExternalEmployeeNumber,DateUsed)
SELECT dateadd(second, ROWVAL, DateVale)
FROM
( SELECT B.[FIRST NAME] FNAME, B.[LAST NAME] LNAME , B.EMAIL EMAIL , GETDATE() DateVale , ROW_NUMBER ( )
OVER (ORDER BY B.[FIRST NAME], B.[LAST NAME] , B.EMAIL) ROWVAL
FROM dbo.[EOP_REMs$] B where B.[last name] is not null and B.[first name] is not null and B.[email] is not null
and NOT EXISTS ( SELECT 1 FROM employee E WHERE B.[first name] = E.[firstname] AND B.[email] = E.[email] AND B.[last name] = E.[lastname] )
) X
OUTPUT INSERTED.ExternalEmployeeNumber , FNAME , LNAME , EMAIL
INTO #EmployeeNew([Employee#],[FirstName],[LastName],[Email]);
In the code part above, i am using Fname, Lname and Email other than the inserted column.
It is giving me an error , invalid reference of the Fname, Lname, Email column name ?
Can you help me out. As i said i implemented this using Merge and its working but i need to implement this in SQL 2005.
Thanks and Regards
Dipz
Sorry Dipz, you don’t have access to that information in an INSERT statement.
Interesting but this method does not actually allow you to pickup the values applied with an IDENTITY column as they so not appear in the INSERTED table.
Suppose I had better write a loop then, good job I am covering a rare event.
Correction, the IDENTITY column does appear in the INSERTED table, but not in the target table.
So v useful actually. (ahem)
Hi Pete – yes. 🙂
Hi Rob,
The audit table part of your query does not quiet work as expected. Although it is capturing the changes into #someaudittable it is still also performing the merge action on the #tmp table.
Is there any way to prevent the actual merge on #tmp and just getting the ‘proposed’ changes into #someaudittable?
Thanks,
Ritesh
Can you output to a file?