
Sometimes a forum response should just be a blog post… so here’s something I wrote over at http://dba.stackexchange.com/a/86765/4103.
The question was somewhat staged I think, being from Paul White (@sql_kiwi), who definitely knows this stuff already.
His question:
I often need to select a number of rows from each group in a result set.
For example, I might want to list the ‘n’ highest or lowest recent order values per customer.
In more complex cases, the number of rows to list might vary per group (defined by an attribute of the grouping/parent record). This part is definitely optional/for extra credit and not intended to dissuade people from answering.
What are the main options for solving these types of problems in SQL Server 2005 and later? What are the main advantages and disadvantages of each method?
AdventureWorks examples (for clarity, optional)
- List the five most recent recent transaction dates and IDs from the TransactionHistory table, for each product that starts with a letter from M to R inclusive.
- Same again, but with n history lines per product, where n is five times the DaysToManufactureProduct attribute.
- Same, for the special case where exactly one history line per product is required (the single most recent entry by TransactionDate, tie-break on TransactionID.
And my answer:
Let’s start with the basic scenario.
If I want to get some number of rows out of a table, I have two main options: ranking functions; or TOP.
First, let’s consider the whole set from Production.TransactionHistory for a particular ProductID:
|
1 |
[crayon-6a17736b6bdf7845942766 inline="true" ]SELECT h.TransactionID, h.ProductID, h.TransactionDate FROM Production.TransactionHistory h WHERE h.ProductID = 800; |
[/crayon]
This returns 418 rows, and the plan shows that it checks every row in the table looking for this – an unrestricted Clustered Index Scan, with a Predicate to provide the filter. 797 reads here, which is ugly.
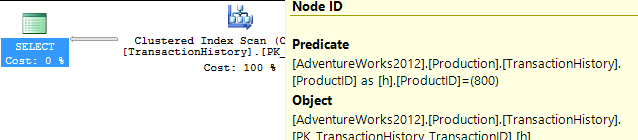
So let’s be fair to it, and create an index that would be more useful. Our conditions call for an equality match on ProductID, followed by a search for the most recent by TransactionDate. We need the TransactionID returned too, so let’s go with: CREATE INDEX ix_FindingMostRecent ON Production.TransactionHistory (ProductID, TransactionDate) INCLUDE (TransactionID);.
Having done this, our plan changes significantly, and drops the reads down to just 3. So we’re already improving things by over 250x or so…
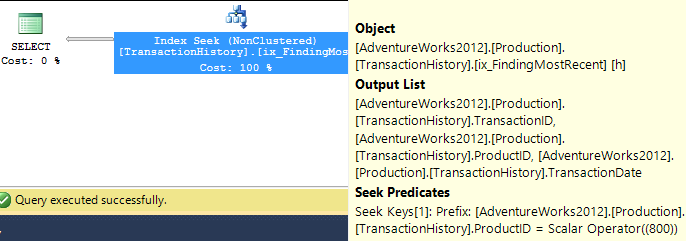
Now that we’ve levelled the playing field, let’s look at the top options – ranking functions and TOP.
|
1 |
[crayon-6a17736b6be08895370106 inline="true" ]WITH Numbered AS ( SELECT h.TransactionID, h.ProductID, h.TransactionDate, ROW_NUMBER() OVER (ORDER BY TransactionDate DESC) AS RowNum FROM Production.TransactionHistory h WHERE h.ProductID = 800 ) SELECT TransactionID, ProductID, TransactionDate FROM Numbered WHERE RowNum <= 5; SELECT TOP (5) h.TransactionID, h.ProductID, h.TransactionDate FROM Production.TransactionHistory h WHERE h.ProductID = 800 ORDER BY TransactionDate DESC; |
[/crayon]
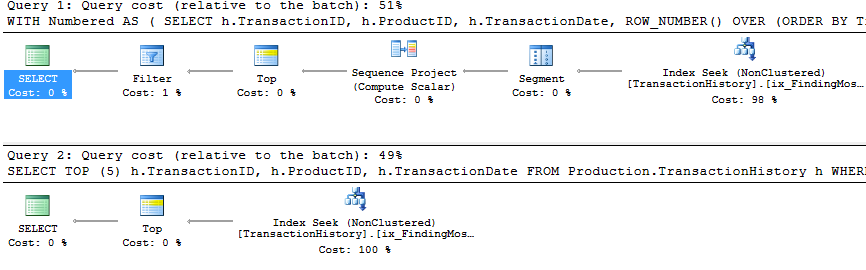
You will notice that the second ( TOP) query is much simpler than the first, both in query and in plan. But very significantly, they both use TOP to limit the number of rows actually being pulled out of the index. The costs are only estimates and worth ignoring, but you can see a lot of similarity in the two plans, with the ROW_NUMBER() version doing a tiny amount of extra work to assign numbers and filter accordingly, and both queries end up doing just 2 reads to do their work. The Query Optimizer certainly recognises the idea of filtering on a ROW_NUMBER() field, realising that it can use a Top operator to ignore rows that aren’t going to be needed. Both these queries are good enough – TOP isn’t so much better that it’s worth changing code, but it is simpler and probably clearer for beginners.
So this work across a single product. But we need to consider what happens if we need to do this across multiple products.
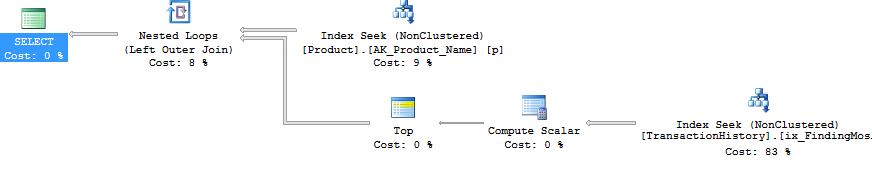
The iterative programmer is going to consider the idea of looping through the products of interest, and calling this query multiple times, and we can actually get away with writing a query in this form – not using cursors, but using APPLY. I’m using OUTER APPLY, figuring that we might want to return the Product with NULL, if there are no Transactions for it.
|
1 |
[crayon-6a17736b6be1d703071470 inline="true" ]SELECT p.Name, p.ProductID, t.TransactionID, t.TransactionDate FROM Production.Product p OUTER APPLY ( SELECT TOP (5) h.TransactionID, h.ProductID, h.TransactionDate FROM Production.TransactionHistory h WHERE h.ProductID = p.ProductID ORDER BY TransactionDate DESC ) t WHERE p.Name >= 'M' AND p.Name < 'S'; |
[/crayon]
The plan for this is the iterative programmers’ method – Nested Loop, doing a Top operation and Seek (those 2 reads we had before) for each Product. This gives 4 reads against Product, and 360 against TransactionHistory.
Using ROW_NUMBER(), the method is to use PARTITION BY in the OVER clause, so that we restart the numbering for each Product. This can then be filtered like before. The plan ends up being quite different. The logical reads are about 15% lower on TransactionHistory, with a full Index Scan going on to get the rows out.

Significantly, though, this plan has an expensive Sort operator. The Merge Join doesn’t seem to maintain the order of rows in TransactionHistory, the data must be resorted to be able to find the rownumbers. It’s fewer reads, but this blocking Sort could feel painful. Using APPLY, the Nested Loop will return the first rows very quickly, after just a few reads, but with a Sort, ROW_NUMBER() will only return rows after a most of the work has been finished.
Interestingly, if the ROW_NUMBER() query uses INNER JOIN instead of LEFT JOIN, then a different plan comes up.

This plan uses a Nested Loop, just like with APPLY. But there’s no Top operator, so it pulls all the transactions for each product, and uses a lot more reads than before – 492 reads against TransactionHistory. There isn’t a good reason for it not to choose the Merge Join option here, so I guess the plan was considered ‘Good Enough’. Still – it doesn’t block, which is nice – just not as nice as APPLY.
The PARTITION BY column that I used for ROW_NUMBER() was h.ProductID in both cases, because I had wanted to give the QO the option of producing the RowNum value before joining to the Product table. If I use p.ProductID, we see the same shape plan as with the INNER JOIN variation.
|
1 |
[crayon-6a17736b6be44365565590 inline="true" ]WITH Numbered AS ( SELECT p.Name, p.ProductID, h.TransactionID, h.TransactionDate, ROW_NUMBER() OVER (PARTITION BY p.ProductID ORDER BY h.TransactionDate DESC) AS RowNum FROM Production.Product p LEFT JOIN Production.TransactionHistory h ON h.ProductID = p.ProductID WHERE p.Name >= 'M' AND p.Name < 'S' ) SELECT Name, ProductID, TransactionID, TransactionDate FROM Numbered n WHERE RowNum <= 5; |
[/crayon]
But the Join operator says ‘Left Outer Join’ instead of ‘Inner Join’. The number of reads is still just under 500 reads against the TransactionHistory table.

Anyway – back to the question at hand…
We’ve answered question 1, with two options that you could pick and choose from. Personally, I like the APPLY option.
To extend this to use a variable number (question 2), the 5 just needs to be changed accordingly. Oh, and I added another index, so that there was an index on Production.Product.Name that included the DaysToManufacture column.
|
1 |
[crayon-6a17736b6be51453715176 inline="true" ]WITH Numbered AS ( SELECT p.Name, p.ProductID, p.DaysToManufacture, h.TransactionID, h.TransactionDate, ROW_NUMBER() OVER (PARTITION BY h.ProductID ORDER BY h.TransactionDate DESC) AS RowNum FROM Production.Product p LEFT JOIN Production.TransactionHistory h ON h.ProductID = p.ProductID WHERE p.Name >= 'M' AND p.Name < 'S' ) SELECT Name, ProductID, TransactionID, TransactionDate FROM Numbered n WHERE RowNum <= 5 * DaysToManufacture; SELECT p.Name, p.ProductID, t.TransactionID, t.TransactionDate FROM Production.Product p OUTER APPLY ( SELECT TOP (5 * p.DaysToManufacture) h.TransactionID, h.ProductID, h.TransactionDate FROM Production.TransactionHistory h WHERE h.ProductID = p.ProductID ORDER BY TransactionDate DESC ) t WHERE p.Name >= 'M' AND p.Name < 'S'; |
[/crayon]
And both plans are almost identical to what they were before!
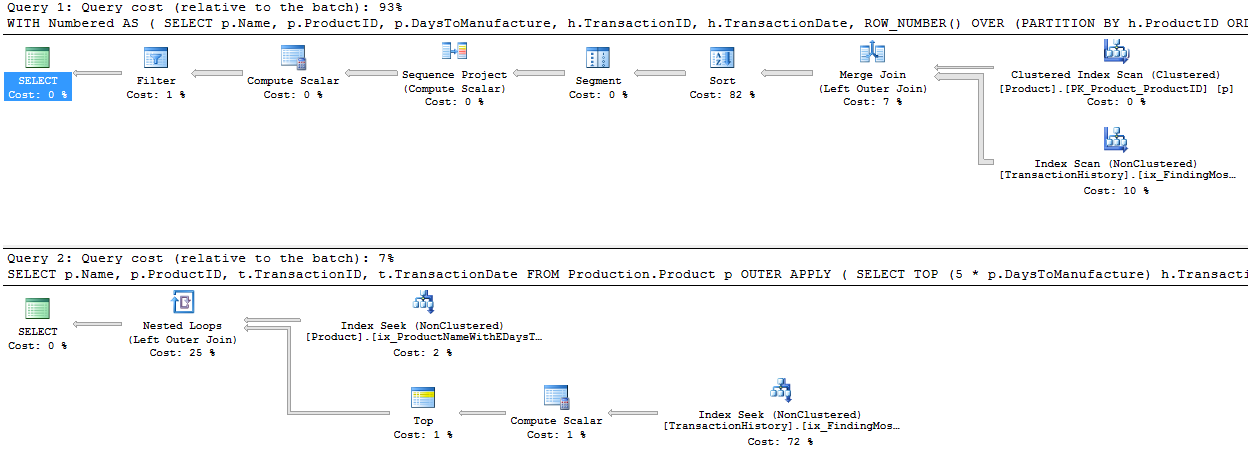
Again, ignore the estimated costs – but I still like the TOP scenario, as it is so much more simple, and the plan has no blocking operator. The reads are less on TransactionHistory because of the high number of zeroes in DaysToManufacture, but in real life, I doubt we’d be picking that column. 😉
One way to avoid the block is to come up with a plan that handles the ROW_NUMBER() bit to the right (in the plan) of the join. We can persuade this to happen by doing the join outside the CTE. (Edited because of a silly typo that meant that I turned my Outer Join into an Inner Join.)
|
1 2 |
[crayon-6a17736b6be65966604948 inline="true" ]WITH Numbered AS ( SELECT h.TransactionID, h.ProductID, h.TransactionDate, ROW_NUMBER() OVER (PARTITION BY ProductID ORDER BY TransactionDate DESC) AS RowNum FROM Production.TransactionHistory h ) SELECT p.Name, p.ProductID, t.TransactionID, t.TransactionDate FROM Production.Product p LEFT JOIN Numbered t ON t.ProductID = p.ProductID AND t.RowNum <= 5 * p.DaysToManufacture WHERE p.Name >= 'M' AND p.Name < 'S'; |
[/crayon]

The plan here looks simpler – it’s not blocking, but there’s a hidden danger.
Notice the Compute Scalar that’s pulling data from the Product table. This is working out the 5 * p.DaysToManufacture value. This value isn’t being passed into the branch that’s pulling data from the TransactionHistory table, it’s being used in the Merge Join. As a Residual.

So the Merge Join is consuming ALL the rows, not just the first however-many-are-needed, but all of them and then doing a residual check. This is dangerous as the number of transactions increases. I’m not a fan of this scenario – residual predicates in Merge Joins can quickly escalate. Another reason why I prefer the APPLY/TOP scenario.
In the special case where it’s exactly one row, for question 3, we can obviously use the same queries, but with 1 instead of 5. But then we have an extra option, which is to use regular aggregates.
|
1 |
[crayon-6a17736b6be73629941750 inline="true" ]SELECT ProductID, MAX(TransactionDate) FROM Production.TransactionHistory GROUP BY ProductID; |
[/crayon]
A query like this would be a useful start, and we could easily modify it to pull out the TransactionID as well for tie-break purposes (using a concatenation which would then be broken down), but we either look at the whole index, or we dive in product by product, and we don’t really get a big improvement on what we had before in this scenario.
But I should point out that we’re looking at a particular scenario here. With real data, and with an indexing strategy that may not be ideal, mileage may vary considerably. Despite the fact that we’ve seen that APPLY is strong here, it can be slower in some situations. It rarely blocks though, as it has a tendency to use Nested Loops, which many people (myself included) find very appealing.
I haven’t tried to explore parallelism here, or dived very hard into question 3, which I see as a special case that people rarely want based on the complication of concatenating and splitting. The main thing to consider here is that these two options are both very strong.
I prefer APPLY. It’s clear, it uses the Top operator well, and it rarely causes blocking.
This Post Has 7 Comments
Hi Rob
If the dens is high,for example we have 10 customers with 100000000 orders then probably using cross apply which produces seek (if index exists ) will be optimal option.. On the other hand, row number will be better to have a scan if the dens is low..Just my two cents
Hi Uri – Merry Christmas!
Yes, your mileage can vary depending on various factors. However, you should still be wary of Sort operators, and it’s good to be aware of the options. I generally prefer APPLY, but have been known to use both.
Rob
Hi Rob – Mery Christmas !
We want eliminate sorts by having an appropriate index. I like the concept POC introduced by Itzik Be-Gan to have an index on F (filtering) P (Partition) O (Orders) and C – Covering :-)))
Thanks
Yes – the index I’m using there matches that.
Rob, I am pretty sure your final query has a very common logic flaw that is causing incorrect results. You are filtering in the WHERE clause based on the LEFT JOINed table. This restricts the rows improperly, giving 961 rows of output instead of the expected 1045. Shouldn’t the query be written thusly:
WITH Numbered AS
(
SELECT h.TransactionID, h.ProductID, h.TransactionDate, ROW_NUMBER() OVER (PARTITION BY ProductID ORDER BY TransactionDate DESC) AS RowNum
FROM Production.TransactionHistory h
)
SELECT p.Name, p.ProductID, t.TransactionID, t.TransactionDate
FROM Production.Product p
LEFT JOIN Numbered t ON t.ProductID = p.ProductID
AND t.RowNum <= 5 * p.DaysToManufacture
WHERE p.Name >= ‘M’ AND p.Name < ‘S’;
Or perhaps you intended to include only the WHERE clause rows? In this case an INNER JOIN would be more appropriate I think.
Yes – my focus on that last query was to demonstrate the impact of the residual predicate. I’ll tweak the post at some point soon.
Fixed now, Kevin. Thanks for pointing out my silly error.