
I’m sure you’ve heard by now that casting a datetime to a date is still SARGable. Like, that if you have an index on a datetime column (such as DateTimeCol in dbo.SomeTable), then you will get a seek even if you use a predicate like “WHERE CAST(DateTimeCol as date) = @DateParam”. Sargability is all about whether your predicates can be used for a Seek, and it’s something I’ve been preaching about for a very long time.
The trouble with this is that casting a datetime column to a date isn’t actually a Sargable predicate. It feels like one, but it’s not. Either way, I thought I’d write about this for T-SQL Tuesday, which is hosted this month by Brent Ozar (@brento). He asks us to write about our favourite data types, and I figure that talking about the pseudo-sargability of datetime-date conversion fits. (It was either that or write about how a unique index on datetimeoffset complains that ‘20210101 00:00 +10:30’ and ‘20210101 00:30 +11:00’ are the same value, even though they are clearly a little different. Maybe I’ll do both… Edit: I did.)
Sargability is about the fact that an index is on the values in a column, and that if you’re actually looking for something else, then the index doesn’t work. So converting a column from one datatype to another doesn’t cut it.
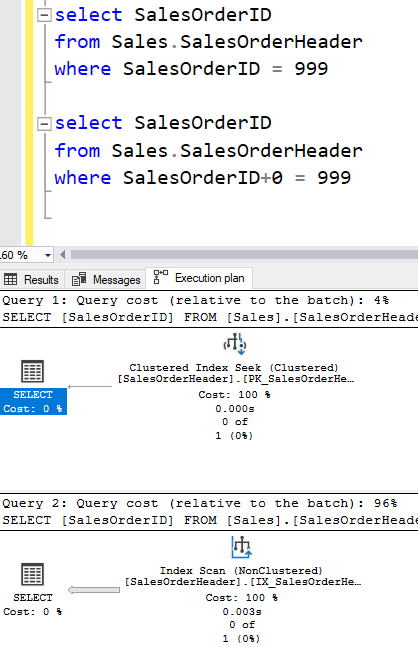
It doesn’t even work to add zero to a integer value. That’s enough to confuse the Query Optimizer into thinking that an index might not be right (and this is still the case if we use OPTION (RECOMPILE) so that it doesn’t try to parameterise the query). It’s easy for us to see that the order of things in the index isn’t changed by adding a constant value, but the Query Optimizer doesn’t look for this. I had a Connect item open for years about this.
So what’s special about converting from datetime to date? Well, it’s about being able to add a helper predicate to the mix. (This is also how LIKE works against strings.) The Query Optimizer knows that all the values must be in a certain range, so that it can seek to that range. It works out this range using an internal function called GetRangeThroughConvert. It does a good job on this for LIKE, but doesn’t do such a good job with dates.
Let me show you.
First I’m going to create a table called Times and put 100,000 rows in it, one per minute from the start of the year until roughly now. It’s actually in a couple of days’ time, mid-morning on March 11th.
[sql]
DROP TABLE IF EXISTS dbo.Times;
GO
CREATE TABLE dbo.Times (TimeAndDate datetime, CONSTRAINT pkTimes PRIMARY KEY (TimeAndDate));
GO
INSERT dbo.Times (TimeAndDate)
SELECT TOP (100000) DATEADD(minute,ROW_NUMBER() OVER (ORDER BY (SELECT 1))-1,’20210101′)
FROM master..spt_values t1, master..spt_values t2;
GO
[/sql]
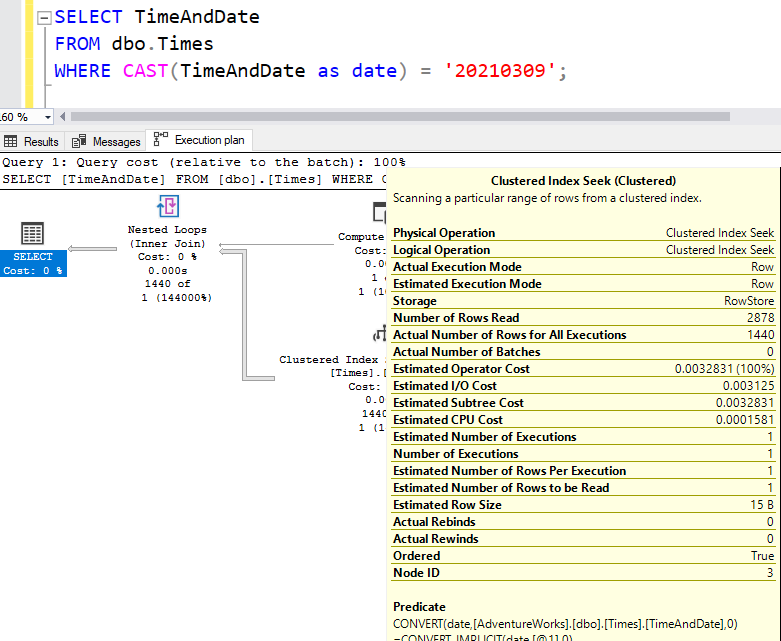
Now when I query this table to find all the rows from today, I see an Index Seek and can be happy. “Obviously” this is sargable.
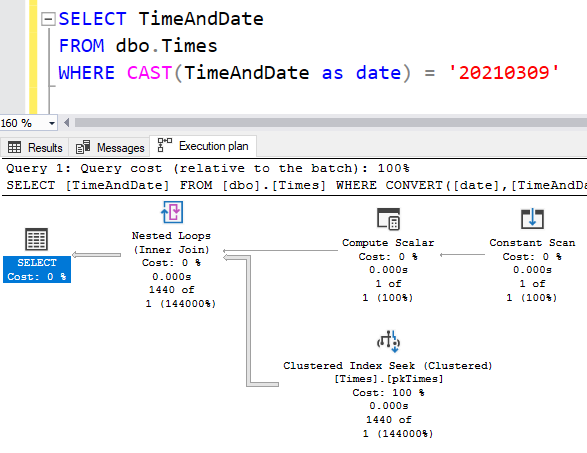
But it’s not really. The properties of that Clustered Index Seek show that our WHERE clause is being used as the Residual Predicate, and that our Seek Predicate is based on the Expressions created in that Compute Scalar operator.
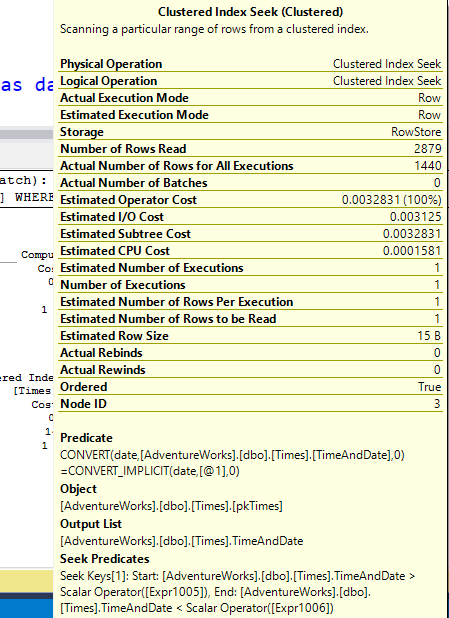
Now, you’ll notice that the operators used in that Seek predicate are > and <. Greater-than and less-than. Not Greater-than-or-equal and less-than. This is a range which is exclusive at both ends. And this is interesting because if I want to write out a date range myself, I do it using an inclusive start and an exclusive end, like:
[sql]
SELECT TimeAndDate
FROM dbo.Times
WHERE TimeAndDate >= ‘20210309’
AND TimeAndDate < '20210310'
;
[/sql]
So I got to thinking about this. I wasn’t quite curious enough to pull up the debugger to try to see what the values were, but I did do some investigation.
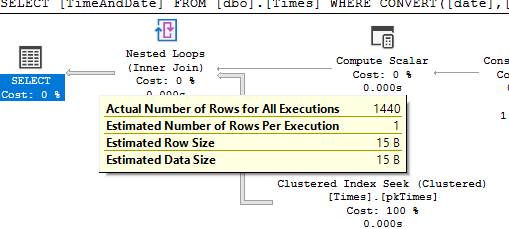
Notice in that tooltip I showed earlier, that the “Actual Number of Rows for All Executions” property says 1440. That’s the number of minutes in a day, so that makes sense. But the “Number of Rows Read” property is 2879. This means that the Seek Predicate is returning 2879 rows, and then the Residual Predicate (shown as just “Predicate”) is filtering these down to the 1440 that actually produce the correct value when converted to the date type.
2879 is one less than the number of minutes in two days. I figure the “one less” bit is because it’s an exclusive-exclusive range. But still it’s a range which is twice as big. It’s not “a little bit bigger”, it’s twice as big as it needs to be. To compare this with LIKE:
When LIKE knows what values are being used, it doesn’t use those ComputeScalar & ConstantScan operators, and we see helper predicates that do an inclusive-exclusive range:
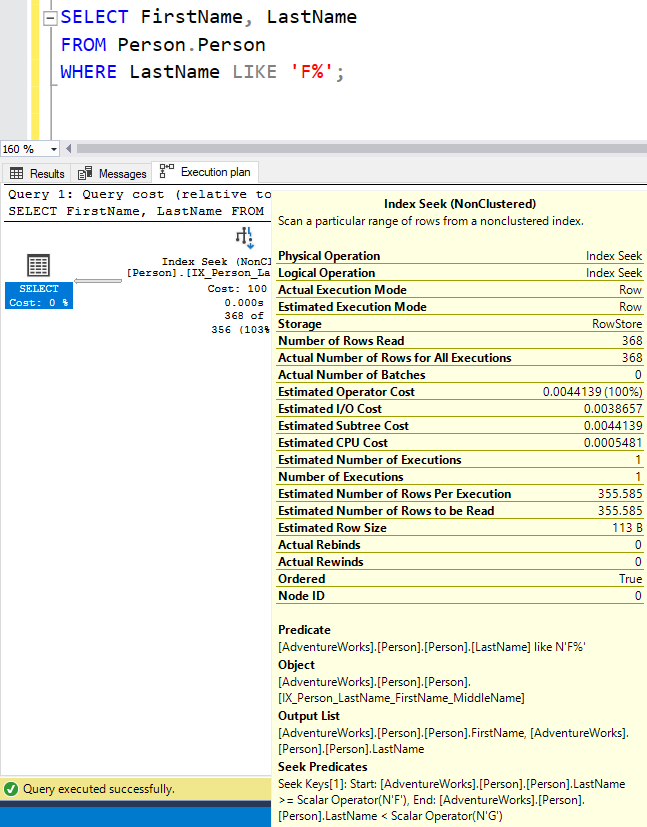
But when we use a parameter, we have the expressions and an exclusive-exclusive range, but the same number of rows read as returned.
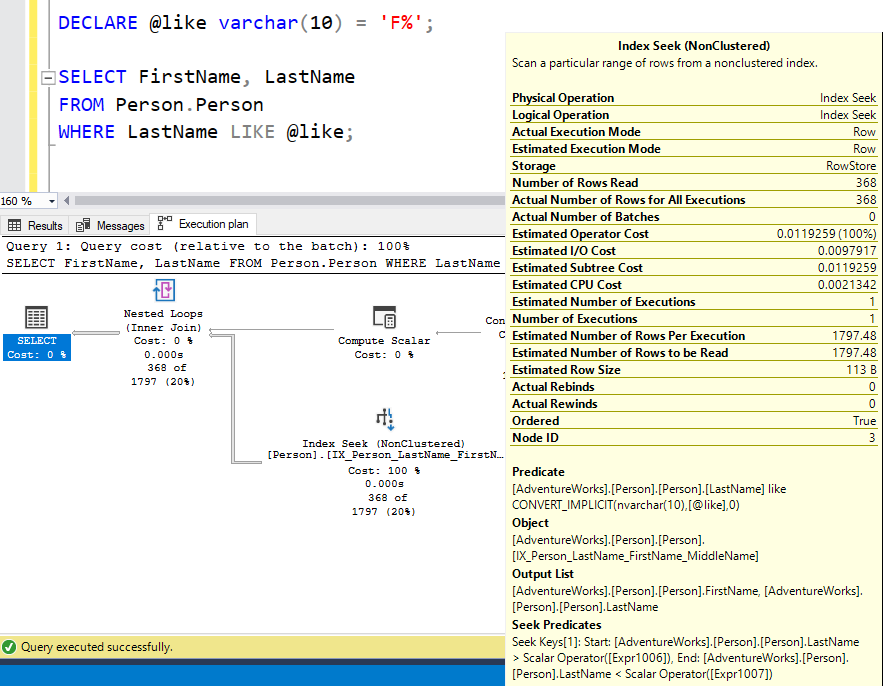
The Query Optimizer clearly understands how to do the range for LIKE.
But with the date conversion, twice as big.
Back to what that time period range is…
To figure this out, I started deleting rows from my table. I figured I’ll be able to see the range by when the Number of Rows Read value starts dropping.
First I deleted rows from mid-morning March 10th on:
[sql]
DELETE
FROM dbo.Times
WHERE TimeAndDate >= ‘20210310 10:00’;
[/sql]
And the size of the range didn’t change.
I removed all the datetime values from the 10th and the range didn’t change. And all the datetime values from before the 8th. Only when I deleted ‘20210308 00:01’ did the range start shrinking.
So the range of my helper predicate hits the day before my date as well as the day I actually want. TWO days. Twice as big.
It certainly sounds like I’d be better off running my query using my own range predicate, typing out my inclusive-exclusive range instead of relying on the supposed sargability of casting as date. When I write this out, my plan becomes a lot more simple-looking, because it doesn’t have to work out the range, but the plans tell me the cost is greater!
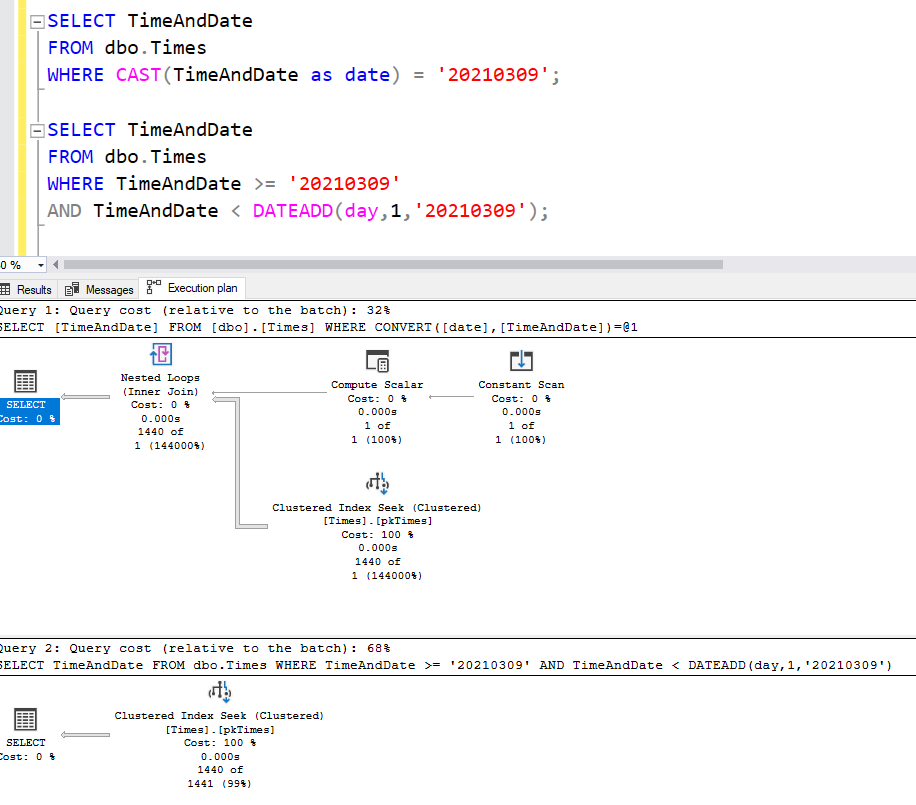
It’s lying though. It thinks the first query is cheaper because it does a bad job of estimating. It thinks there’s only one row being produced when there are actually way more.
To try to even things up, let’s try using a parameter for the date in both queries.
And whoa! It’s even worse. Now when we do the range ourselves, it thinks it’s 93% of the batch, and the simplicity of the plan has gone out the window.
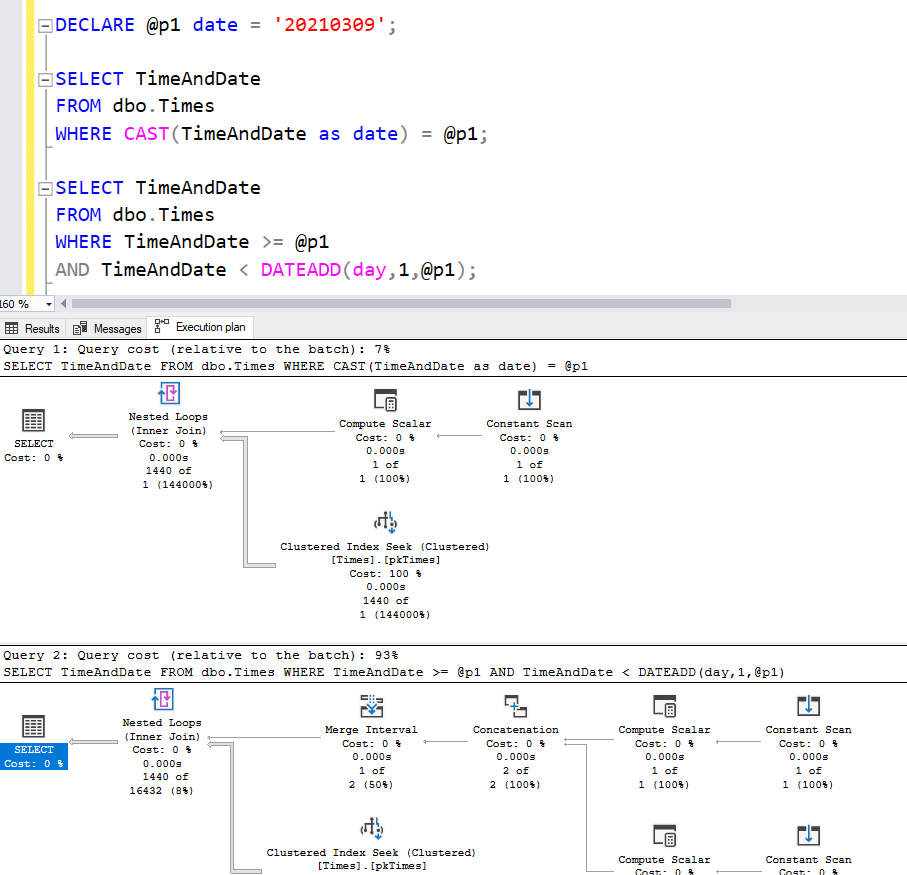
And yet this “more expensive” plan is actually better. The Index Seek looks through 1440 rows to find the 1440 rows, while the CAST query looks through 2879 rows. The estimate on this second version says that over 16,000 rows might be produced (which is what causes it to be 93% of the batch). But if I’m going to be passing 1440 rows through a query, I’d rather guess 16,000 than guess just 1.
The conclusion of all this is to point out that although we often refer casually to the idea that a datetime column cast to a date column is sargable, it’s actually not quite, and you’re better off handling your ranges yourself.
This Post Has One Comment
Pingback: #TSQL2sday 136 Wrap-Up: Your Favorite (and Least Favorite) Data Types - Brent Ozar Unlimited®