
Datetimeoffset is an interesting data type, because there are multiple ways to represent the same value. And I don’t mean like using a string to store “1” and “1.0”, I mean the fact that I might have inserted a value in one time zone, but need to be query it in a different one.
[sql]
CREATE TABLE dbo.TimesOffsets (TimeAndDateAndOffset datetimeoffset, CONSTRAINT pkTimesOffset PRIMARY KEY(TimeAndDateAndOffset))
GO
INSERT dbo.TimesOffsets(TimeAndDateAndOffset)
VALUES (‘20210101 00:00 +10:30’);
GO
SELECT TimeAndDateAndOffset
FROM dbo.TimesOffsets
WHERE TimeAndDateAndOffset = ‘20210101 00:30 +11:00’;
[/sql]
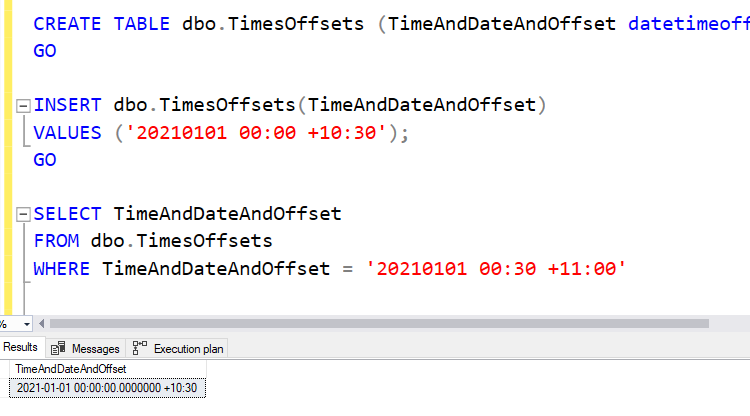
Notice that I inserted a value in the time zone UTC+10:30, and queried it back in UTC+11, and the value that it gave me in the results is in UTC+10:30. Clearly the system knows that the value in the table was stored in UTC+10:30, and would store something different if I had told it to insert the value in UTC+11 (feel free to try it and see that it’ll return the same value that you inserted, whichever time zone your WHERE clause value is in).
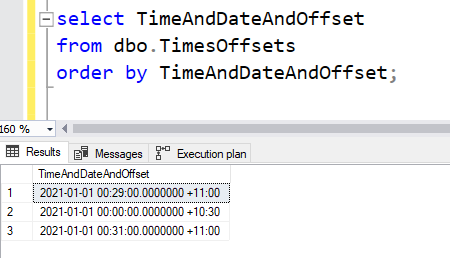
Sort order understands this too. If I insert other rows, it knows what order they are actually in, regardless of where in the world those times happen.
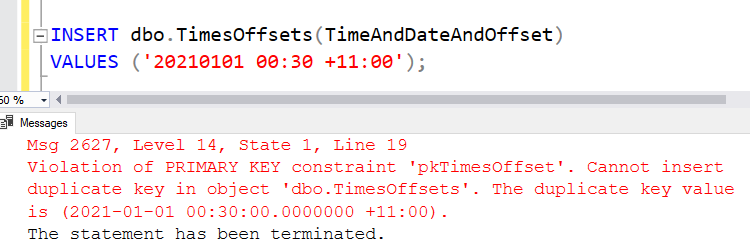
And as I have a unique index on this, it won’t let me insert 00:30 in UTC+11, because 00:00 in UTC+10:30 is already there. It tells me “Msg 2627, Level 14, State 1, Line 19. Violation of PRIMARY KEY constraint ‘pkTimesOffset’. Cannot insert duplicate key in object ‘dbo.TimesOffsets’. The duplicate key value is (2021-01-01 00:30:00.0000000 +11:00).”
I’m okay with this. They are definitely the same value, even if they are written differently. The same thing happens with strings in different collations, because they sort to the same value. Müller and Mueller will clash in a table with a German PhoneBook collation (and yes, that’s what the German collations are called, complete with a capital ‘B’ in the middle of ‘PhoneBook’).
[sql]
DROP TABLE IF EXISTS dbo.Names;
GO
CREATE TABLE dbo.Names (LastName varchar(100) COLLATE German_PhoneBook_CI_AI, CONSTRAINT pkGermanNames PRIMARY KEY(LastName));
GO
INSERT dbo.Names (LastName) VALUES (‘Müller’);
GO
INSERT dbo.Names (LastName) VALUES (‘Mueller’);
–Fails
[/sql]
So you see, the time zone thing isn’t about whether they are actually identical or not. It’s about whether they are considered the same based on the things that the SQL engine uses to consider them equal. When you’re dealing with data that is case-insensitive, it will consider that ‘FARLEY’ and ‘Farley’ are the same, and complain if I’m trying to have both those values in a unique index.
And for a fun trick, let’s consider what happens with GROUP BY or DISTINCT.
For this, I’m going to first recreate those tables with non-unique indexes. Still using indexes, just non-unique ones.
[sql]
DROP TABLE IF EXISTS dbo.TimesOffsets;
GO
CREATE TABLE dbo.TimesOffsets (TimeAndDateAndOffset datetimeoffset, INDEX cixTDO CLUSTERED (TimeAndDateAndOffset))
GO
INSERT dbo.TimesOffsets(TimeAndDateAndOffset)
VALUES (‘20210101 00:00 +10:30’);
GO
INSERT dbo.TimesOffsets(TimeAndDateAndOffset)
VALUES (‘20210101 00:30 +11:00’);
GO
SELECT DISTINCT TimeAndDateAndOffset
FROM dbo.TimesOffsets
ORDER BY TimeAndDateAndOffset ASC
GO
SELECT DISTINCT TimeAndDateAndOffset
FROM dbo.TimesOffsets
ORDER BY TimeAndDateAndOffset DESC
[/sql]
And the results show different values according to whether we sort the data ascending or descending.
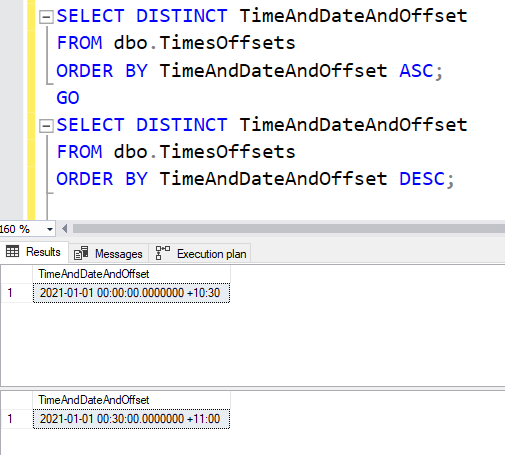
All those times someone told you the order of the data didn’t affect what the results were, just what order they were in… yeah.
And if I run the script again but insert the rows in the opposite order…
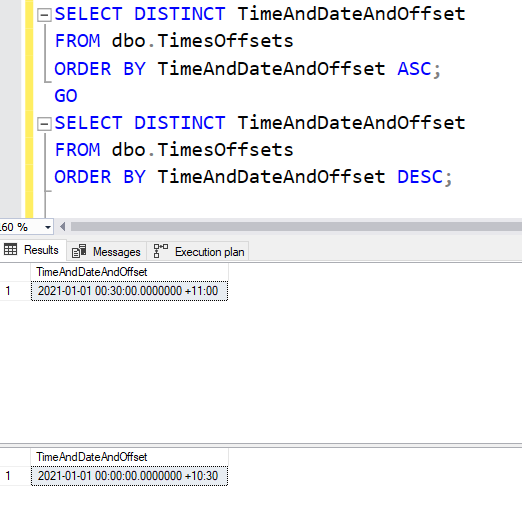
You see, the rows are in the table in the order they were inserted. And when we are moving through the index either forwards or backwards, we’re coming across values, and the version of the value is the one that gets seen first. If it moves through it forwards, it’ll (probably) come across the first row that was inserted first. If it moves through it backwards, it’ll (probably) come across the last row first. I say ‘probably’, because there are times that it won’t quite work like this. Parallelism could make this be different. There may have been index rebuilds, or page splits, or the execution plan might decide to do run things differently.
But the idea is there – those two values are the same, even though they’re not.
This post fits into T-SQL Tuesday, hosted this month by Brent Ozar (@brento) on the topic of data types.
This Post Has 2 Comments
Pingback: Beware the width of the covering range - LobsterPot Blogs
Pingback: #TSQL2sday 136 Wrap-Up: Your Favorite (and Least Favorite) Data Types - Brent Ozar Unlimited®