
Deborah Melkin (@dgmelkin) said “give us that rant” in her invitation for this month’s T-SQL Tuesday. And I suspect I’ve been known for getting a little wound up about code that is valid, but which performs badly. The biggest culprit here is non-sargable queries. (There are other common ones, like scalar functions, but this will do for today.)
I’ve given presentations about this stuff for a long time. The most famous is probably from 2010 at SQL Bits – I even have a bit.ly link for it (bit.ly/Sargability)! But coders (Java, C#, whatever) don’t tend to watch videos about T-SQL. I know this because I used to be a coder. Some people reach T-SQL by being a sysadmin and then a DBA. Others (including me) are programmers who start to realise that the data is actually the most important bit of their applications, and want to be good at it. Sargability is required knowledge for writing queries that will perform well. It’s related to how your query can use indexes.
It frustrates me a little that people consider indexes to the realm of DBAs. As if performance is something for a group of people (probably DBAs) different to the person who wrote the query (who is probably a developer). And yet that’s often how it tends to work – DBAs or even external consultants like me have a look at resource-consuming queries and fix them up. Sometimes indexes are added. Sometimes the queries are rewritten. And from time to time, this even feeds back to the developers. But often really not. If the queries are inside stored procedures, then an application patch might replace the procedures with the original (poorly-performing) versions. If an application patch doesn’t replace the procedures… well, that’s a different rant again.
The performance of a query depends on a number of things. Obviously the way that the query is written itself, but also the data structures (heaps and indexes, constraints, and so on) and the statistics. When the query is outside the scope of the person trying to tune the query, we’re left to fixing things through indexes. But if predicates have been created in non-sargable ways, there’s only so much that can be done.
For example, if someone has a query like this, which finds OrderIDs and CustomerIDs for orders placed on the day that was three days ago:
[sql]
SELECT o.OrderID, o.CustomerID
FROM dbo.Orders o
WHERE o.OrderDate >= CONVERT(datetime,CONVERT(date,DATEADD(day,-3,SYSDATETIME())))
AND o.OrderDate < CONVERT(datetime,CONVERT(date,DATEADD(day,-2,SYSDATETIME())));
[/sql]
Then I can tune this by adding an index like this:
[sql]
CREATE INDEX ixDate_withincludes on dbo.Orders (OrderDate)
INCLUDE (OrderID, CustomerID);
[/sql]
I’d actually create it with various other options, such as page compression… but my point here is to create an index that will allow me to find the dates that are in that range, providing OrderID and CustomerID without needing lookups.
This is a good index. It works nicely.

But if the original query was like this:
[sql]
SELECT o.OrderID, o.CustomerID
FROM dbo.Orders o
WHERE DATEDIFF(day,o.OrderDate,SYSDATETIME()) = 3
[/sql]
Then my hands are somewhat tied.
That index I created can still be used, but it won’t support a Seek predicate, because the query isn’t providing a range to locate within ordered data. This is something else. And while you and I can see that the rows we’re looking for will pretty much be all together in a range (time zones notwithstanding), the SQL Query Optimizer doesn’t know this (I wish it did – I’ve asked the folks at Microsoft a lot of times for it). So instead, when this query runs, it begins at the first page of the index and runs through it looking for orders that are in the right range. Oblivious to the fact that they’ll all be clumped together.

The query is logically correct. And it’s fairly easy to read, too. But by applying functions to the values in the OrderDate column, we’re shooting ourselves in the foot. If I can’t change that predicate, I’m missing out on a huge opportunity to tune the query.
Part of my frustration is that the good people who worked on the Query Optimizer back in the days of SQL Server 2008 made some things fairly sargable. Kind of.
[sql]
SELECT o.OrderID, o.CustomerID
FROM dbo.Orders o
WHERE CONVERT(date,o.OrderDate) = CONVERT(date,DATEADD(day,-3,SYSDATETIME()));
[/sql]
This query isn’t really sargable, but the Query Optimizer creates a range predicate so that it can perform in a sargable-like way.
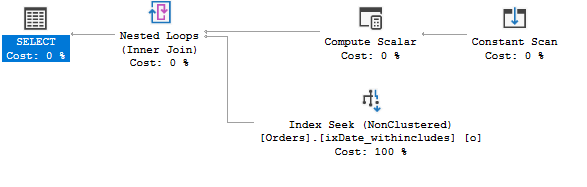
The scalars that are computed are the beginning and end of a range, which I’ve written about extensively before. It’s purely for performance. And it’s great.
It doesn’t happen all the time, mind you. If you cast that value back to datetime for the comparison, it’s doesn’t behave so well, scanning again.
[sql]
SELECT o.OrderID, o.CustomerID
FROM dbo.Orders o
WHERE CONVERT(datetime,CONVERT(date,o.OrderDate)) = CONVERT(datetime,CONVERT(date,DATEADD(day,-3,SYSDATETIME())));
[/sql]

I’m still hoping that the new functions coming in SQL Server 2022, such as DATE_BUCKET, will also have these helper predicates. Otherwise my ranting might be to tell people to keep doing things the old way, using >= and < to compare their dates. I have a draft post about DATE_BUCKET which I haven’t published yet because I’m hoping for good news on this exact issue. I don’t want to write a post that tells people to be careful how they use DATE_BUCKET (or any thing else that might come down the line). I just want these things to be fixed – and to also fix YEAR() and when both YEAR() and MONTH() are used, and so on. And even to fix that “DATEDIFF(day,o.OrderDate,SYSDATETIME()) = 3” pattern (or anti-pattern) that I see so much. I know those dates are clumped together. You know those dates are clumped together. Why can’t the Query Optimizer?
And why can’t the developers who write these predicates know to use the more sargable alternative?
@robfarley.com@bluesky (previously @rob_farley@twitter)